 DCMI 2021
DCMI 2021
Abstract
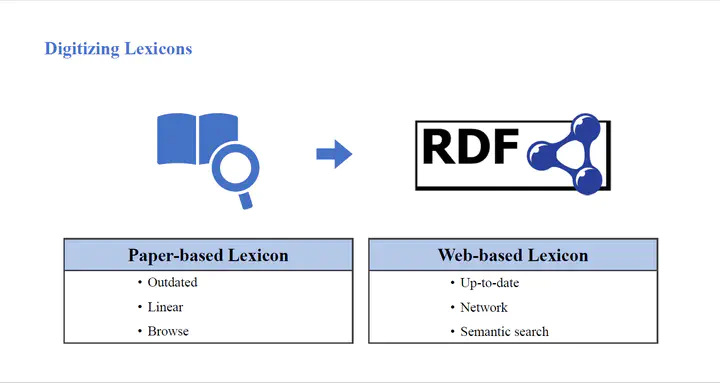
The Chinese Information Retrieval Lexicon was written by Qiyu Zhang, an important figure in the field of LIS, who devoted himself to improve the efficiency of information retrieval. The lexicon formulates a theoretical system of information retrieval with Chinese elements and visions. Linked Data and Semantic Web provide technical support and means for the digitization of the lexicon. Paper-based dictionaries can be converted to electronic dictionaries, and thus be facilitated by sequencing and retrieval. Lexicons, as a type of knowledge organization system, can be generally modeled using SKOS. However, partial entries in the lexicon have multiple senses, which cannot be fully conveyed by simply labeling. Hence, the Ontolex-Lemon model is chosen to enrich and extend specific meaning and to complete the partial encoding of the lexicon. After preparing the initial data, we need VocBench as a multilingual web platform for semantic processing. Sheet2RDF can be used for data format conversion from spreadsheet to triples. The function module allows real-time updates of the entries, and the SPARQL module enables complex queries. The lexical dataset will be integrated into the Linked Open Data Cloud.