Using Karpenter to manage GPU nodes with time-slicing
 architecture
architecture
介绍
对于机器学习,使用 GPU 将加速工作负载的计算。然而,如今公司和用户都更热衷于使用云服务,而非单一的普通机器。有了云计算,你只需要支付服务器的费用,而不需再购置昂贵的显卡。更何况,你很可能不会经常使用它。
这就引出了一个问题——我们又如何优化云服务中 GPU 使用的成本?实际上,当使用虚拟机时,你必须持续为设备付费,即使不真正需要全天候服务。与虚拟机相比,kubernetes 提供了弹性的节点缩放方式,并且更加云原生。因为使用了 eks,所以这里将选择 Karpenter 作为节点缩放器。你可以通过此文档了解更多关于 Karpenter 的信息。
此外,还需要一个 NVIDIA 的k8s 插件。用于 Kubernetes 的 NVIDIA 设备插件是一个Daemonset(确保全部(或者某些)节点上运行一个 Pod 的副本),提供了下述自动化的功能:
- 显示集群每个节点上的 GPU 数量
- 实时追踪GPU 的运行与健康状况
- 在 Kubernetes 集群中运行启用 GPU 的容器
它还支持时间切片。因此,它将允许用户在 Pod (可以在 Kubernetes 中创建和管理的最小可部署计算单元)之间共享 GPU,从而节省成本。
Karpenter 本身为节点提供了自动缩放功能,这意味着只有在需要算力时,才会创建 GPU 实例。并且可以根据配置的实例类型,来调度节点。它可以帮助节省资金,以及更有效地调度节点。
将 GPU 与 Karpenter 一起使用的目的不仅是节省成本,更重要的是,它还提供了一种灵活的方法,来把 GPU 资源调度到 kubernetes 集群中的应用程序。你可能拥有数十个在不同时间段需要 GPU 的应用程序,那么如何以更低成本的方式在云服务器中调度资源,就是件非常重要的事情。
架构
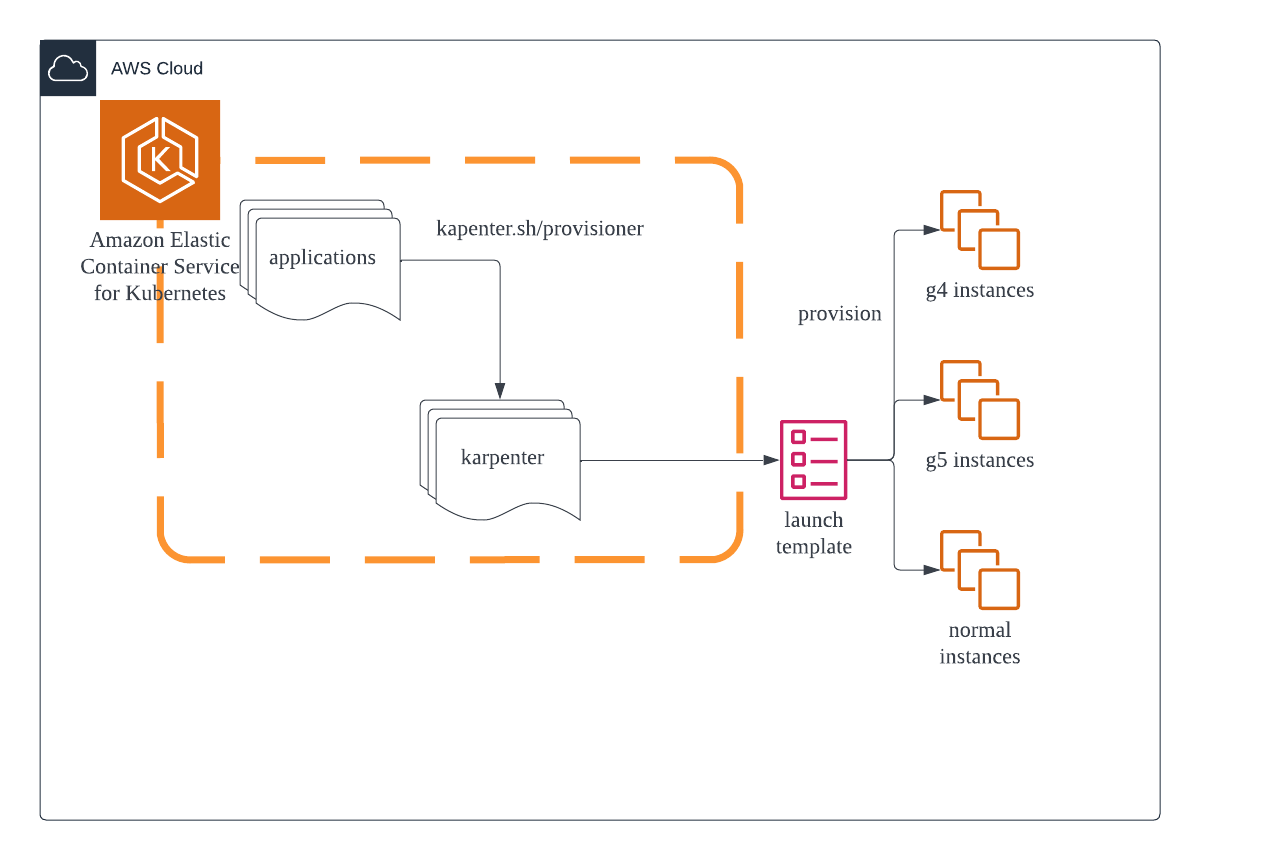
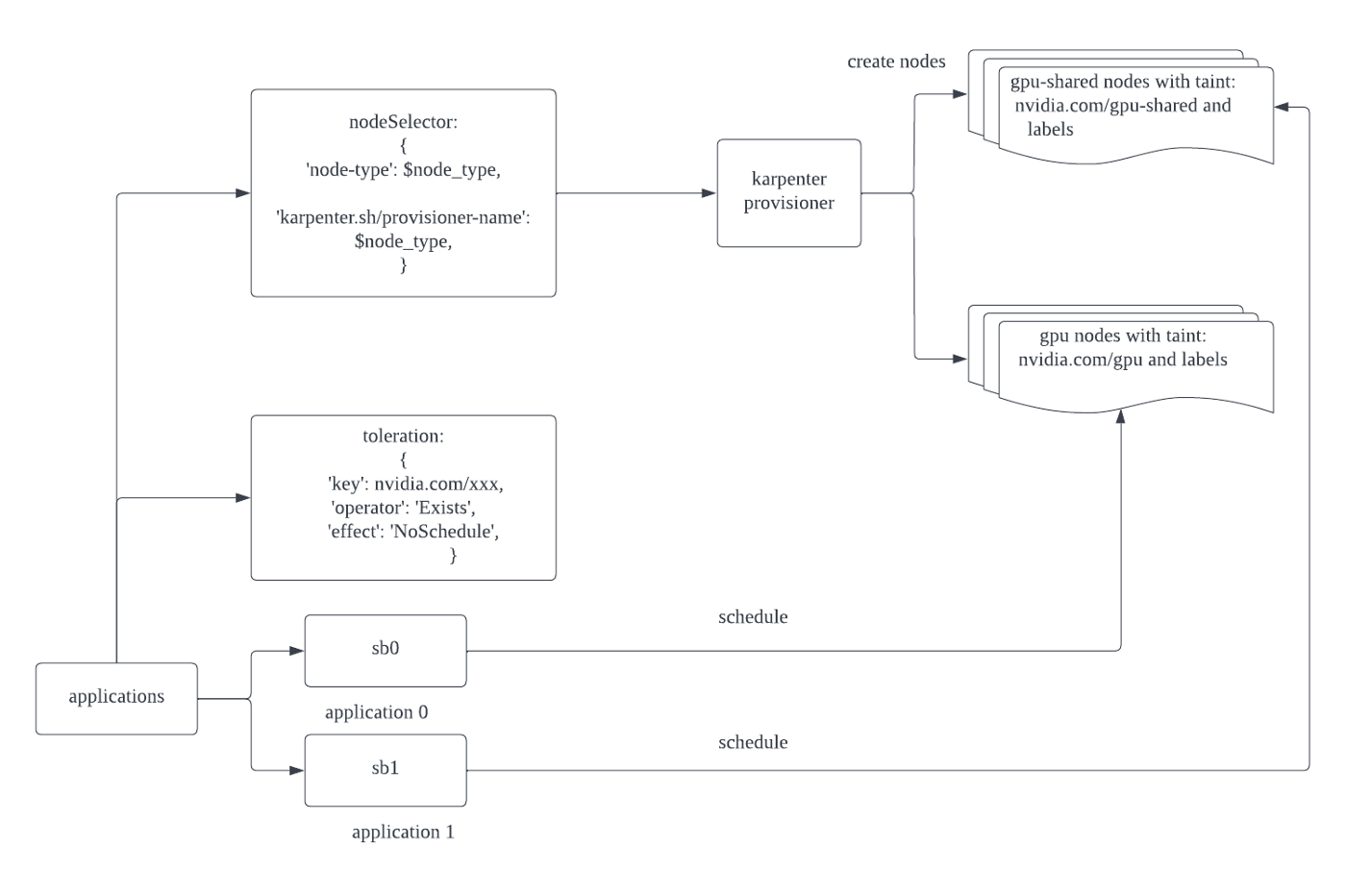
这个架构非常简单易懂:应用程序将选择一个带有选择器(selector)的 karpenter制备器(provisioner)。karpenter制备器将根据启动模板创建节点。
部署
建立架构确实比较简单,剩下的问题是我们将如何部署它。有一些细节仍需要进行考虑:
- 如何将NVIDIA k8s插件部署到仅有GPU的节点
- 如何配置共享GPU节点以使用时间切片,而不影响其他节点
- 如何在启动模板中自动更新节点AMI(Amazon Machine Image),以便节点可以使用最新的镜像
- 如何设置karpenter制备器
下面将逐一讲解。
首先,安装karpenter并使用terraform设置制备器。也可以参考官方文档,在 eks 中手动安装 karpenter。如果你已经有eks以及karpenter,可以跳过这一步。
不妨参考这个GitHub repo。
制备器
resource "kubectl_manifest" "karpenter_provisioner_gpu_shared" {
yaml_body = <<-YAML
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: gpu-shared
spec:
ttlSecondsAfterEmpty: 300
labels:
jina.ai/node-type: gpu-shared
jina.ai/gpu-type: nvidia
nvidia.com/device-plugin.config: shared_gpu
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["g4dn.xlarge", "g4dn.2xlarge", "g4dn.4xlarge", "g4dn.12xlarge"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
taints:
- key: nvidia.com/gpu-shared
effect: "NoSchedule"
limits:
resources:
cpu: 1000
provider:
launchTemplate: "karpenter-gpu-shared-${local.cluster_name}"
subnetSelector:
karpenter.sh/discovery: ${local.cluster_name}
tags:
karpenter.sh/discovery: ${local.cluster_name}
ttlSecondsAfterEmpty: 30
YAML
depends_on = [
helm_release.karpenter
]
}
resource "kubectl_manifest" "karpenter_provisioner_gpu" {
yaml_body = <<-YAML
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: gpu
spec:
ttlSecondsAfterEmpty: 300
labels:
jina.ai/node-type: gpu
jina.ai/gpu-type: nvidia
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["g4dn.xlarge", "g4dn.2xlarge", "g4dn.4xlarge", "g4dn.12xlarge"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
taints:
- key: nvidia.com/gpu
effect: "NoSchedule"
limits:
resources:
cpu: 1000
provider:
launchTemplate: "karpenter-gpu-${local.cluster_name}"
subnetSelector:
karpenter.sh/discovery: ${local.cluster_name}
tags:
karpenter.sh/discovery: ${local.cluster_name}
ttlSecondsAfterEmpty: 30
YAML
depends_on = [
helm_release.karpenter
]
}
启动模板(仅有GPU)
resource "kubectl_manifest" "karpenter_provisioner_gpu" {
yaml_body = <<-YAML
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: gpu
spec:
ttlSecondsAfterEmpty: 300
labels:
jina.ai/node-type: gpu
jina.ai/gpu-type: nvidia
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["g4dn.xlarge", "g4dn.2xlarge", "g4dn.4xlarge", "g4dn.12xlarge"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
taints:
- key: nvidia.com/gpu
effect: "NoSchedule"
limits:
resources:
cpu: 1000
provider:
launchTemplate: "karpenter-gpu-${local.cluster_name}"
subnetSelector:
karpenter.sh/discovery: ${local.cluster_name}
tags:
karpenter.sh/discovery: ${local.cluster_name}
ttlSecondsAfterEmpty: 30
YAML
depends_on = [
helm_release.karpenter
]
}
接下来,我们需要部署具有时间切片配置和默认配置的NVIDIA k8s插件,并设置节点选择器,以便daemonset仅在GPU实例上运行。
nvdp.yml
config:
# ConfigMap name if pulling from an external ConfigMap
name: ""
# Set of named configs to build an integrated ConfigMap from
map:
default: |-
version: v1
flags:
migStrategy: "none"
failOnInitError: true
nvidiaDriverRoot: "/"
plugin:
passDeviceSpecs: false
deviceListStrategy: envvar
deviceIDStrategy: uuid
shared_gpu: |-
version: v1
flags:
migStrategy: "none"
failOnInitError: true
nvidiaDriverRoot: "/"
plugin:
passDeviceSpecs: false
deviceListStrategy: envvar
deviceIDStrategy: uuid
sharing:
timeSlicing:
renameByDefault: false
resources:
- name: nvidia.com/gpu
replicas: 10
nodeSelector:
jina.ai/gpu-type: nvidia
运行下述命令来安装NVIDIA的k8s插件:
$ helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
$ helm repo update
$ helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace nvidia-device-plugin \
--create-namespace -f nvdp.yaml
再之后,使用nodeSelector和toleration部署应用程序。
gpu.yml
kind: Deployment
apiVersion: apps/v1
metadata:
name: test-gpu
labels:
app: gpu
spec:
replicas: 1
selector:
matchLabels:
app: gpu
template:
metadata:
labels:
app: gpu
spec:
nodeSelector:
jina.ai/node-type: gpu
karpenter.sh/provisioner-name: gpu
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
containers:
- name: gpu-container
image: tensorflow/tensorflow:latest-gpu
imagePullPolicy: Always
command: ["python"]
args: ["-u", "-c", "import tensorflow"]
resources:
limits:
nvidia.com/gpu: 1
gpu-shared.yml
kind: Deployment
apiVersion: apps/v1
metadata:
name: test-gpu-shared
labels:
app: gpu-shared
spec:
replicas: 1
selector:
matchLabels:
app: gpu-shared
template:
metadata:
labels:
app: gpu-shared
spec:
nodeSelector:
jina.ai/node-type: gpu-shared
karpenter.sh/provisioner-name: gpu-shared
tolerations:
- key: nvidia.com/gpu-shared
operator: Exists
effect: NoSchedule
containers:
- name: gpu-container
image: tensorflow/tensorflow:latest-gpu
imagePullPolicy: Always
command: ["python"]
args: ["-u", "-c", "import tensorflow"]
resources:
limits:
nvidia.com/gpu: 1
现在,如果部署两个YAML文件,你将在AWS控制台中看到制备的两个节点,或者通过 kubectl get nodes — show-labels命令进行查看。在每个节点上运行nvidia-k8s-plugin后,就可以在应用程序中进行测试。
参考资料
Using Karpenter to manage GPU nodes with time-slicing(原文)