 guidance
guidance
Reference
Model
原有模型:encoder-decoder strcture
将(x1, …, xn)(表示第1-n个词的输入)映射到z = (z1, …, zn)(表示第1-n个词的向量化结果)中 对于解码器,生成长为m的向量(y1, …, ym),在解码器中值是一个一个生成的(auto-regressive, 自回归) 输入又是输出(x → z → y ),同时(y1, …, yt − 1)作为yt的输入
传统思路:
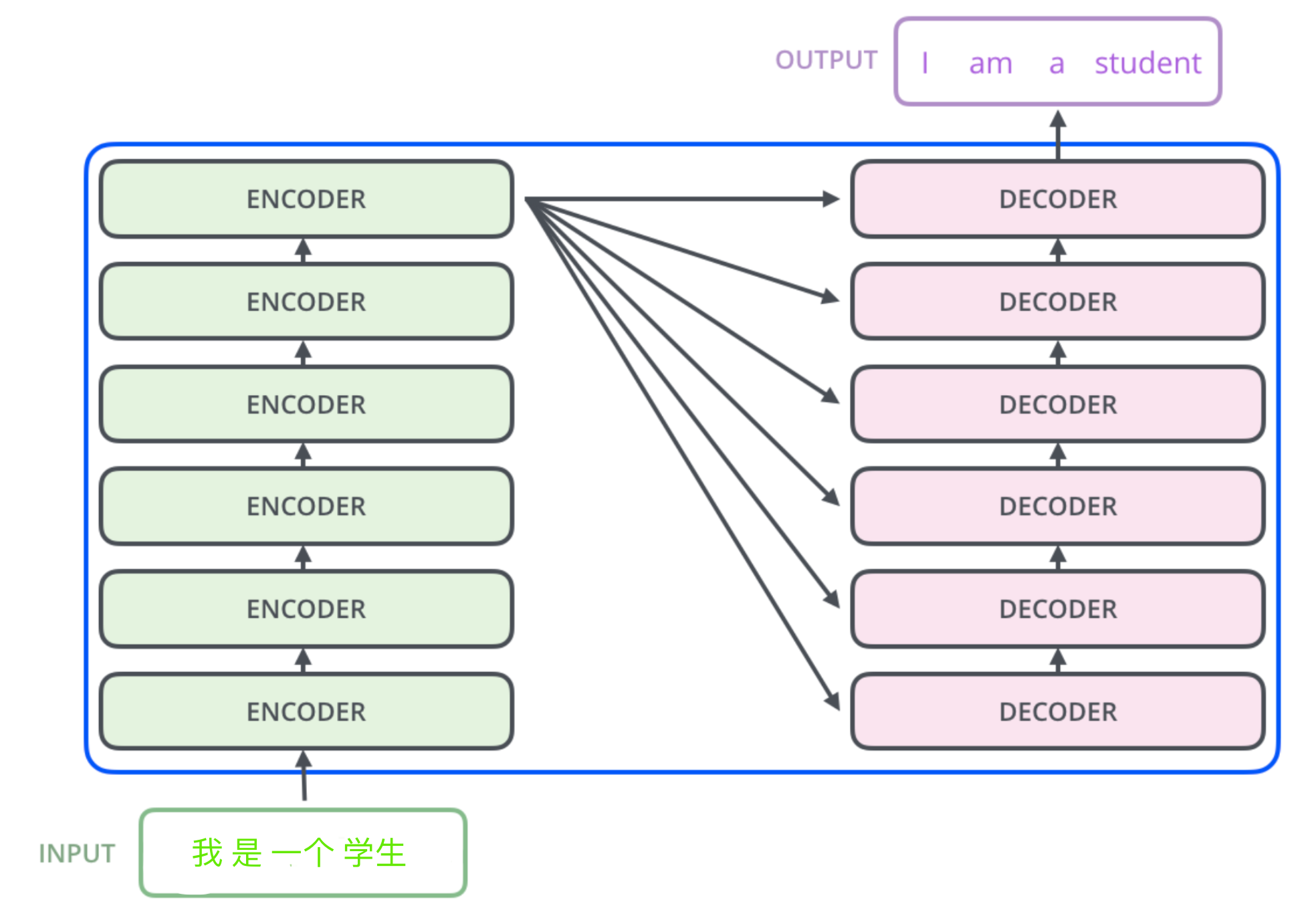
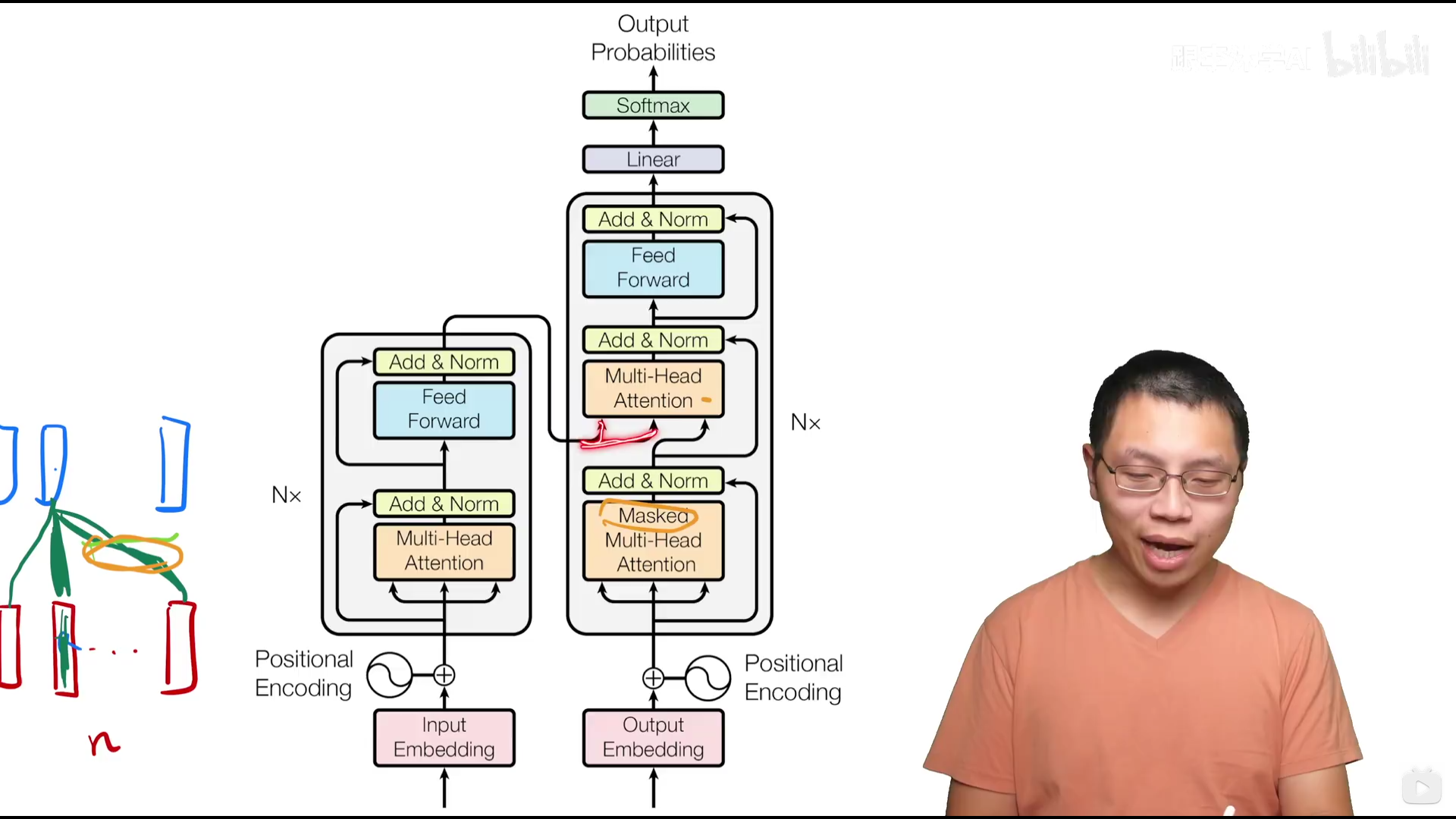
核心架构:
左侧为编码器,右侧为解码器(输入为previous outputs, shifted right即训练的时候掩码一个个往右移)
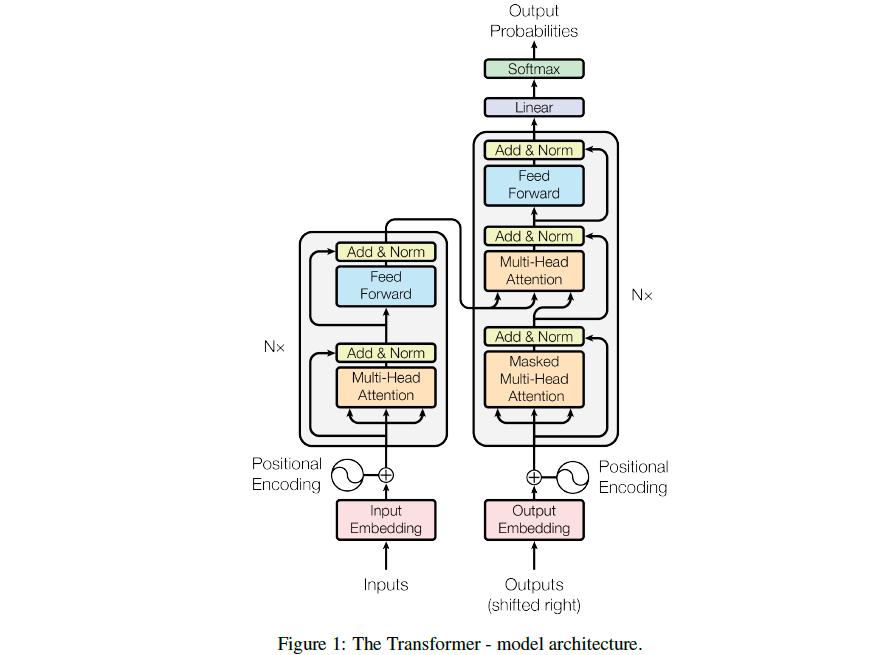
N* 表示有N个 Encoder基本思路是一个注意力层+一个MLP,带有一些残差连接和normalization Decoder多了一个masked multi-head attention
Encoder: 两个超参数, N和dmodel
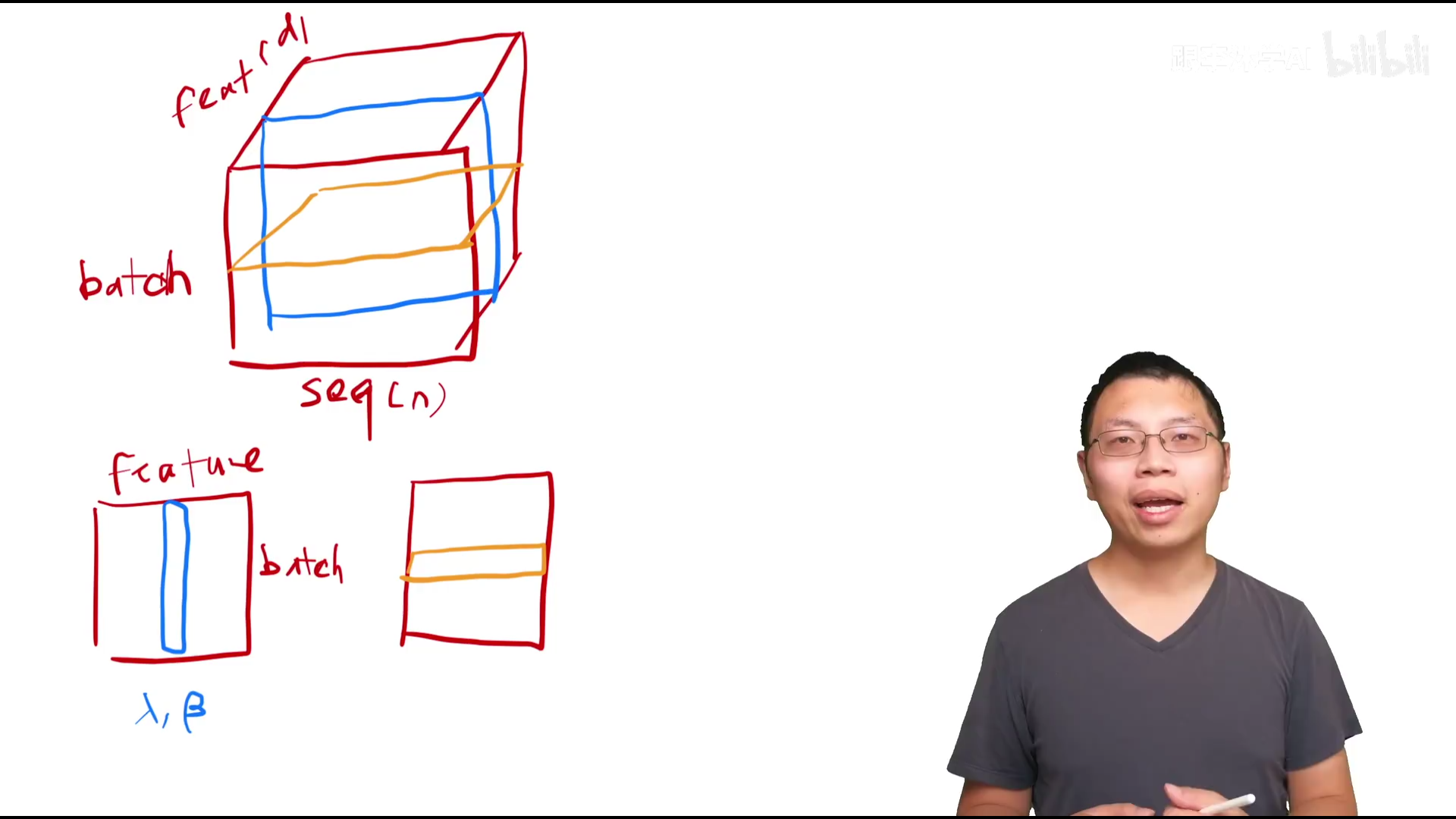
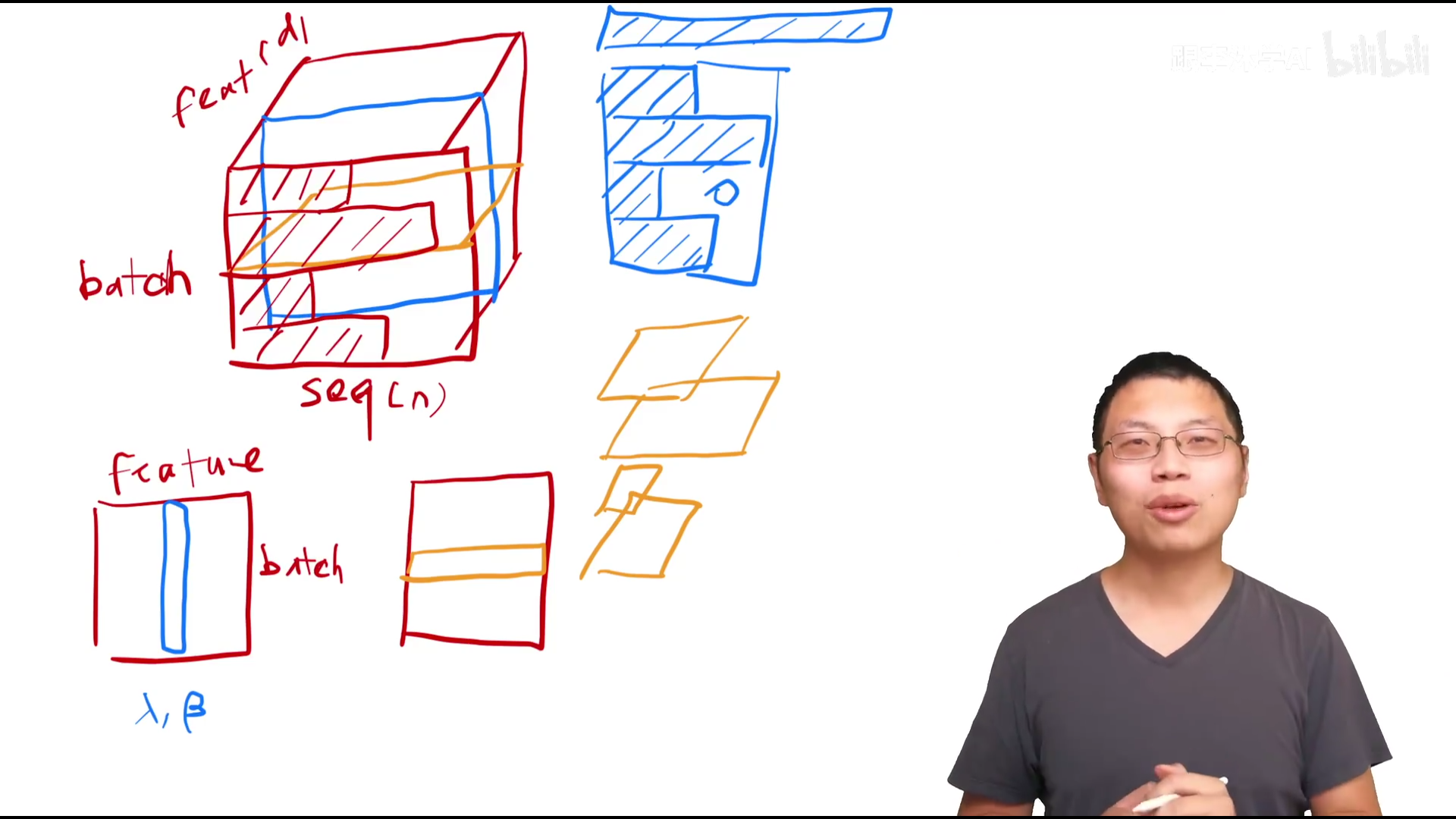
LayerNorm和BatchNorm 1. 输入为二维(对特征和对样本进行处理)

Decoder: 引入了第三个子层,同样用了残差连接和layernorm
自回归:在预测的时候不能看到之后时刻的输出,但是注意力机制可以看到完整输入,所以需要避免,也即预测t时刻的输出时,不应该看到t时刻以后的东西(masked)保证训练和预测行为一致,只在train的时候有mask?
Attention
attention是将序列和成对的key-value做映射 compatibility: 不同的注意力机制有不同算法

Query跟前面的key比较像的时候,前面的权重就会比较大

反之跟后面的key比较像的时候,后面的权重就会比较大
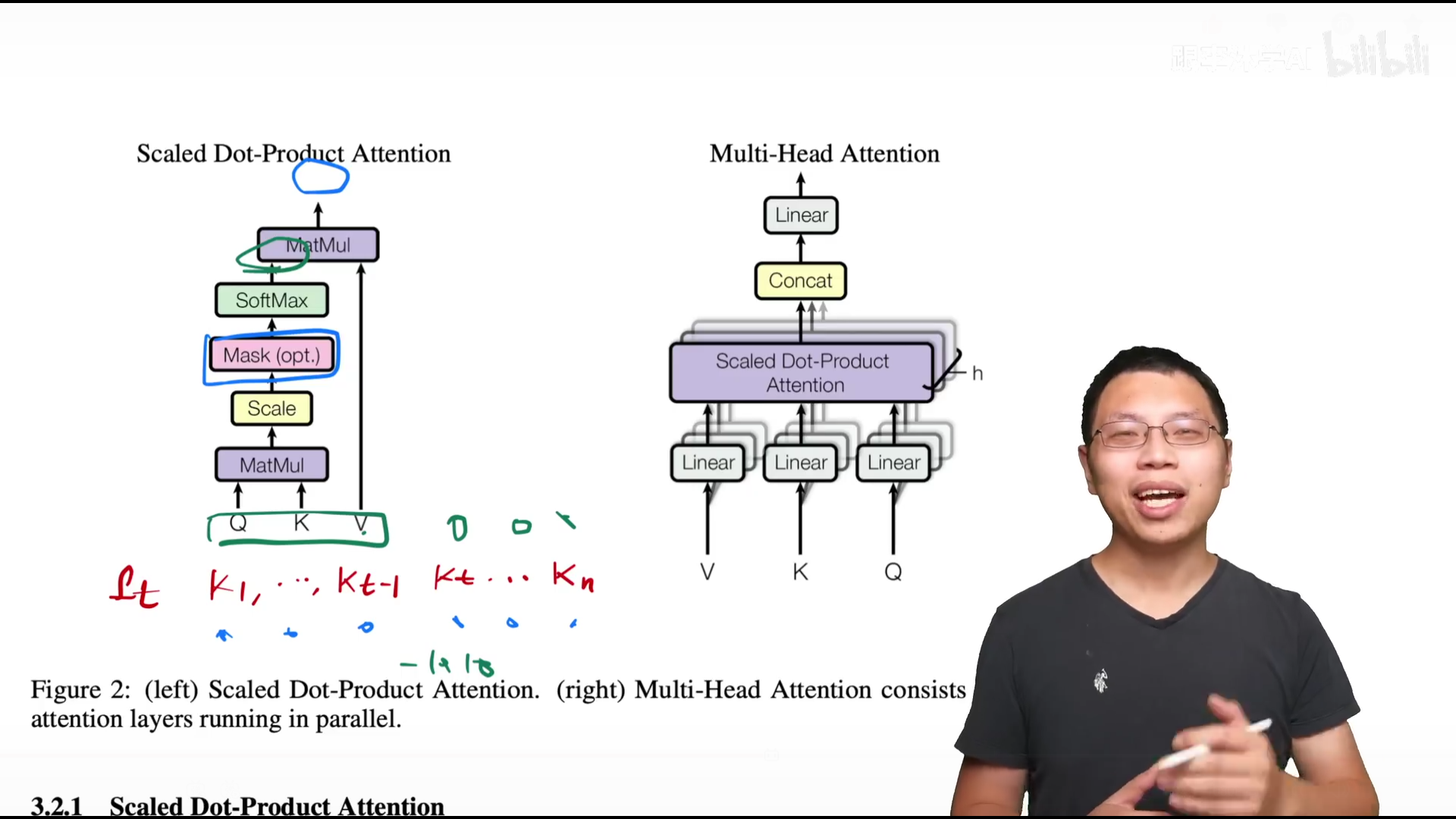
Scaled Dot-Product Attention
把query和key做内积来计算相似度,除以$\sqrt {d_k}$,再放到softmax中得到权重 矩阵乘法:

计算公式
$$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt {d_k}}V)$$
可以很方便的进行并行,跟dot-product比较像,只多了个除以$\sqrt {d_k}$,即scaled,可以增大梯度
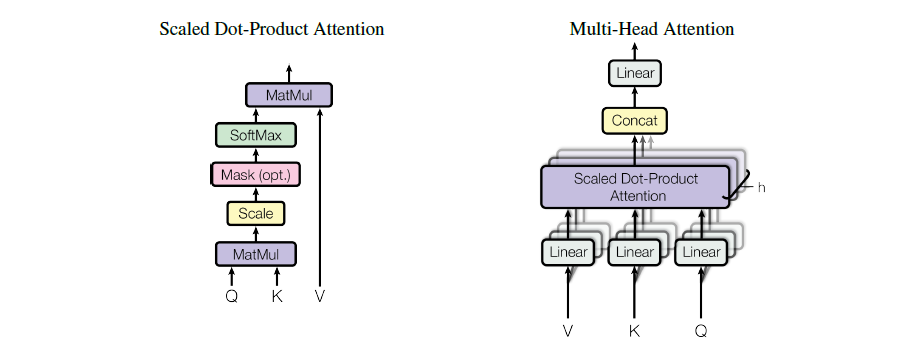
对后面的部分进行处理,趋近于负无限,使得softmax输出为零
Multi-Head Attention
为什么要做multi-head?增加可以学的数量,体现dataset的特征,类似卷积网络中多输出通道 $$ \begin{gather} MultiHead(Q,K,V)=Concat(head_1,…,head_h)W^O\ where \quad head_i=Attention(QW_i^Q,KW_i^K,VW_i^V) \end{gather} $$ 投影到WO中来
Applications of Attention in our Model
三个键头即key,value,query,黄色即masked
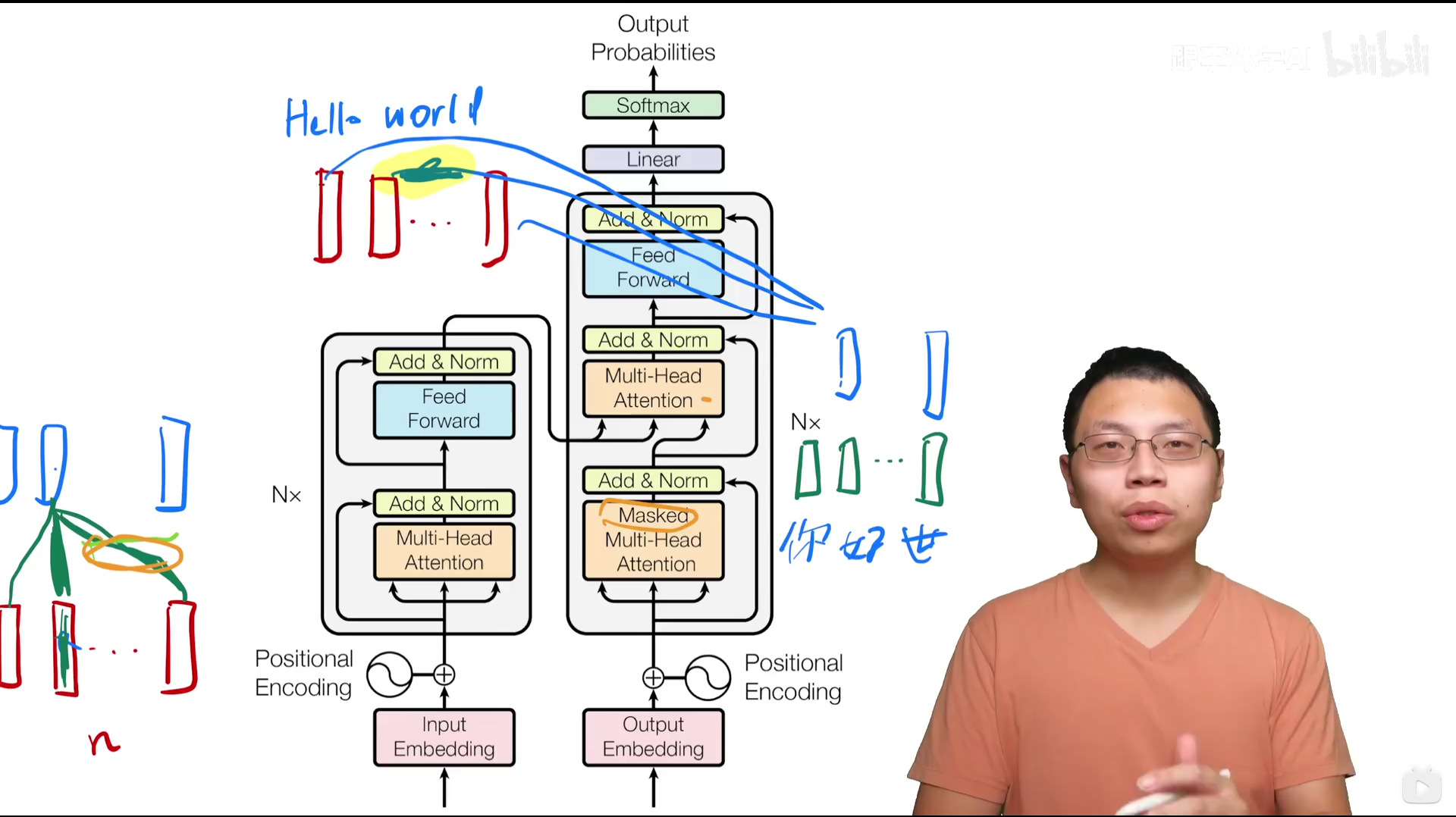
Encoder提供第三个multi-head attention的key和value, Decoder提供query 你好跟hello跟相近,因而会给它比较大的权重,world相关度没那么高,因而权重较小
Position-wise Feed-Forward Networks
类似MLP,但跟position有关系,也即序列中词,对每一个词做一个MLP
线性层+ReLU+线性层
FFN(x) = max(0, xW1 + b1)W2 + b2 不考虑残差连接,layer norm,并且是单头注意力机制
左侧为transformer,绿色部分做了aggregation,因而序列信息已经读取
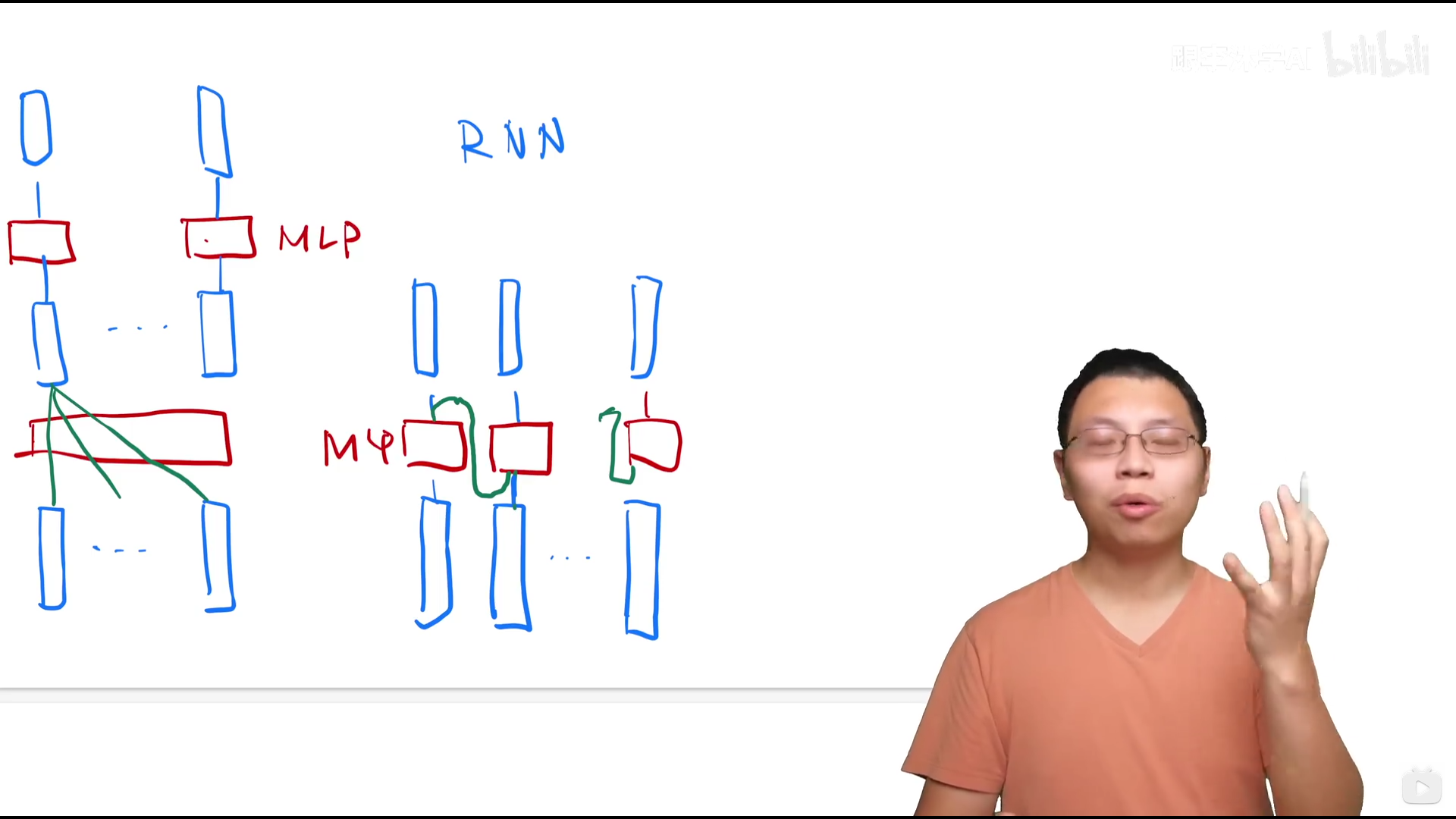
右侧为RNN,传递的方式不同,都含有序列信息,全局和连续的区别
Embeddings and Softmax
Embedding:词变成向量,权重乘以$\sqrt {d_{model}}$
Positional Encoding
在输入里加入时序信息(attention没有),比如在1,…,5位上 每个词有一个长为512的向量(原为数字)
Why Self-Attention

四种层的比较:计算复杂度,顺序计算(下一步计算必须等前面多少步计算完成,和并行度负相关),数据点间距离(需要走多少步) Attention一般用于比较长的序列
Training
byte-pair encoding:把不同变换形式(子根)提出来,字典就会变得比较小 英语和德语用一个字典,因而encoder和decoder共享embedding,权重相同 优化器使用Adam $$ Irate = k*d^{0.5}_{model}min(n^{-0.5},nwarmup_n^{-1.5}) $$
正则化:对每一个子层(多头注意力层和MLP)在进入残差连接和layer norm之前加入0.1 dropout Pdrop = 0.1 Label Smoothing: 把softmax +∞ → 1 1变为0.1
Conclusion
残差连接,layer norm其实缺一不可