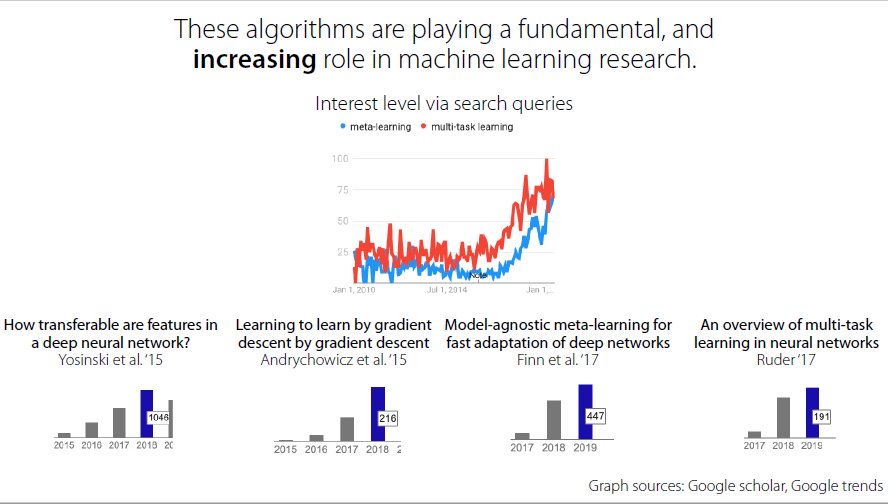
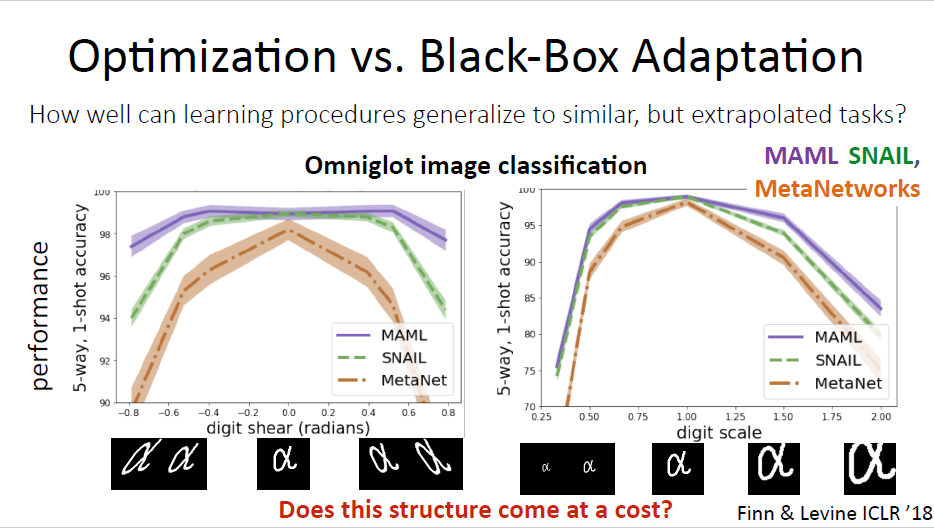
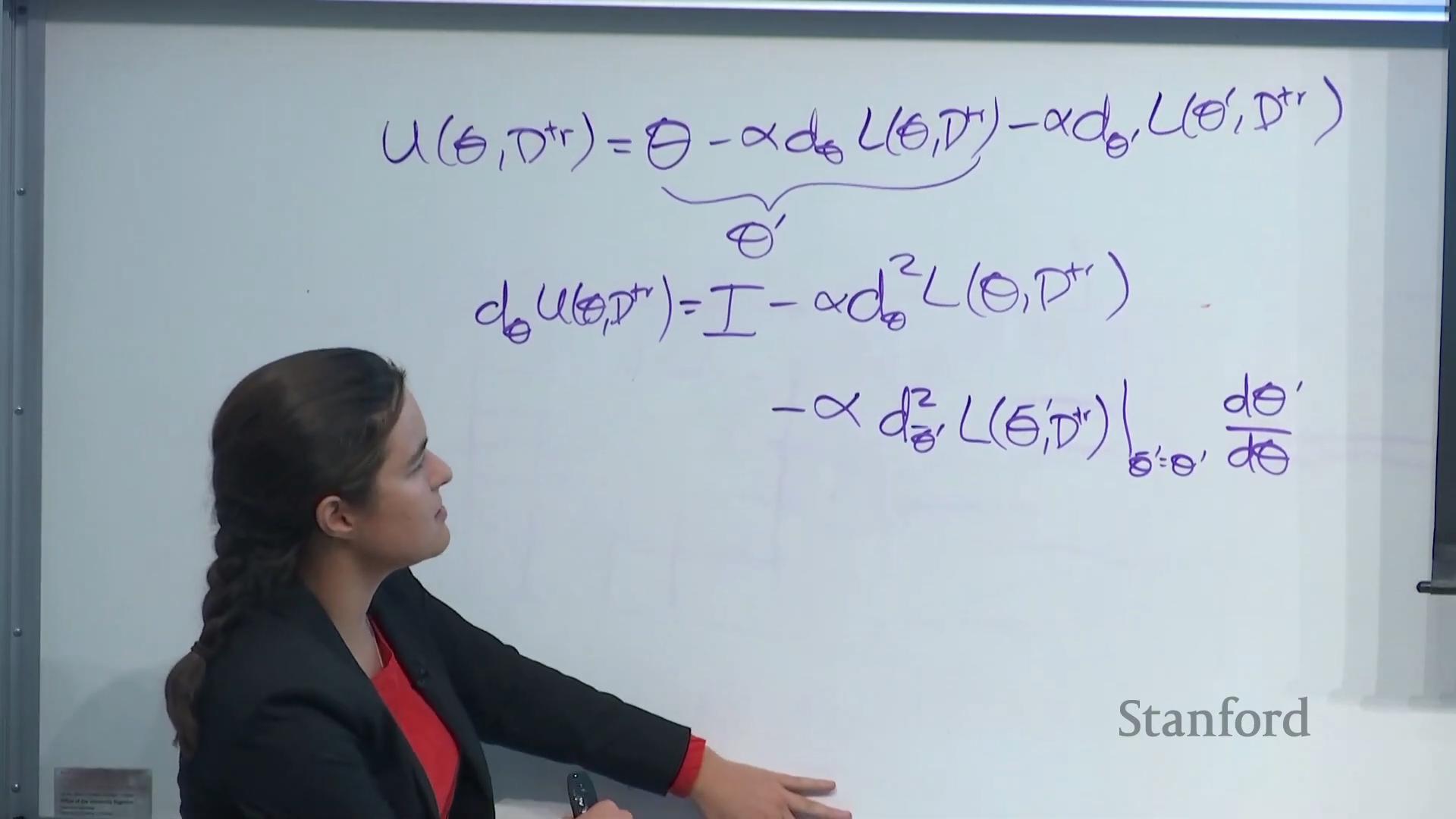Benefits for multi-task learning and meta learning
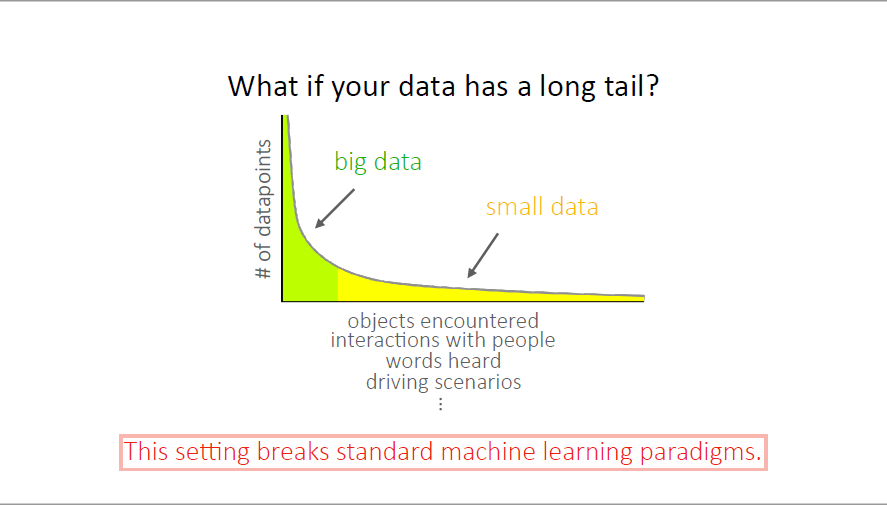
not enough dataset or paired data?
long tail data(such as automatic drive)
How does it work for human?
Brief summary
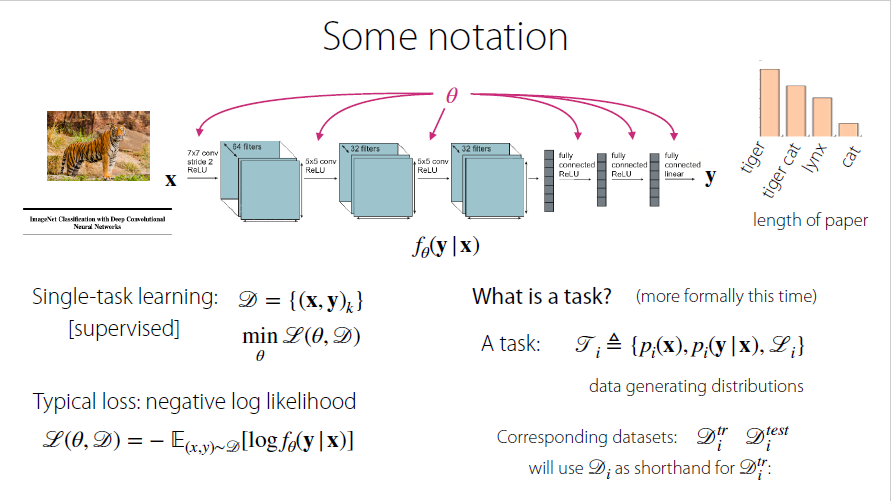
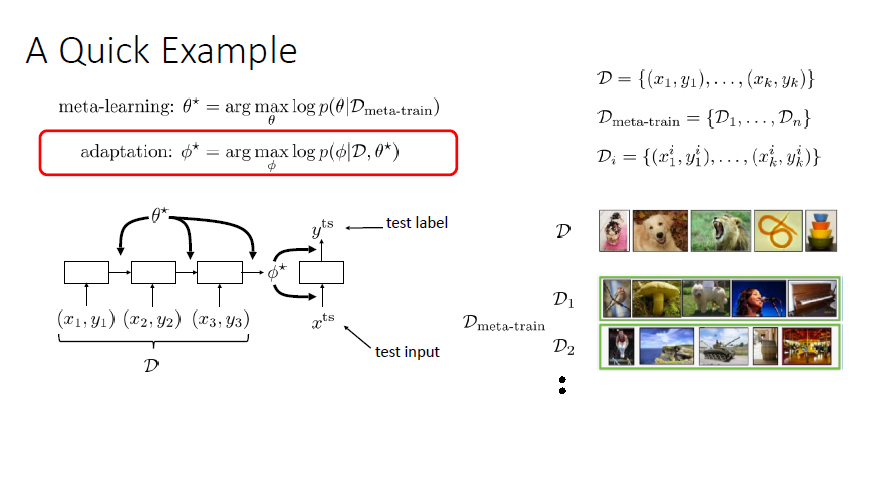
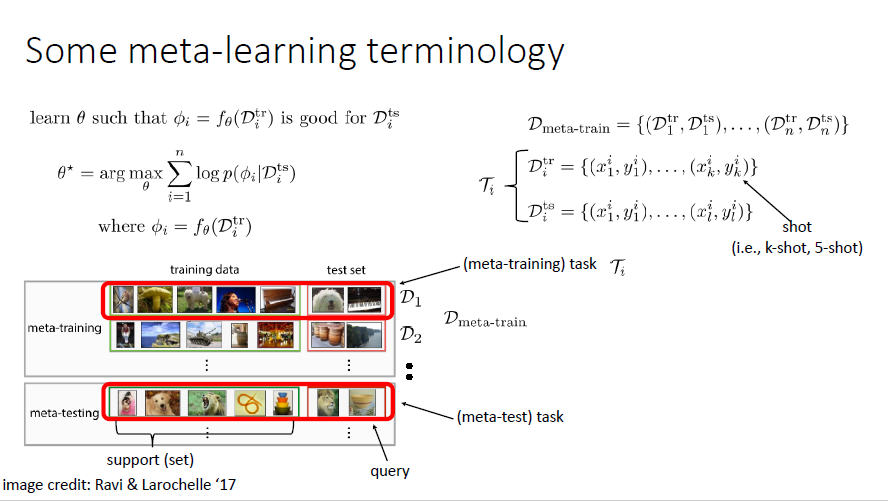
Defining the task
It is the dataset $D$ and loss function $L$ that jointly determines the model $f_\theta$ (task)
cross entropy loss & mean squared loss
MNIST & Fashion MNIST for classifying
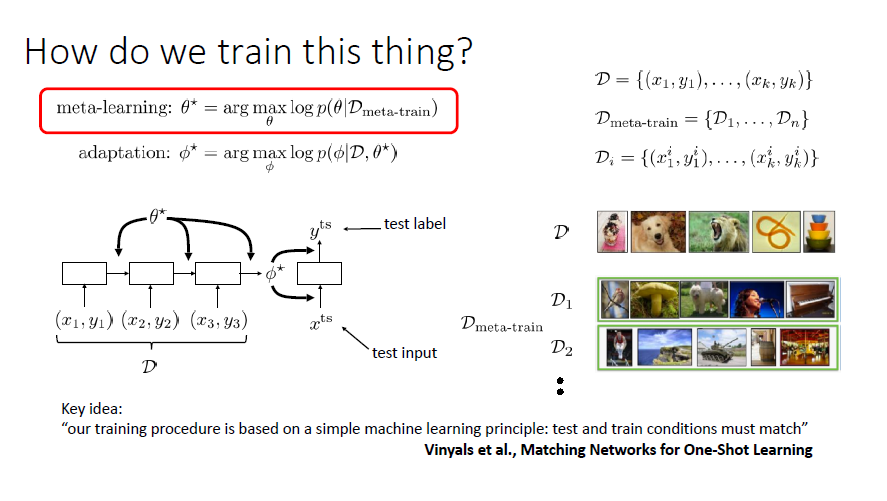
Critical Assumption
If not, splitting into different simple-task learning from scratch may be more rational
Informal Problem Definitions
Q & A
Difference between meta-learning and transfer learning?
I think that one aspect about this problem is that you want to be able to learn a new task more quickly, whereas in transfer learning you may also want to be able to just form a well-performing a new task while in zero shot where you kind of just want to share representations. I actually view transfer learning as something that encapsulates both of these things, uh, where you’re thinking about how you can transfer information between different tasks and that could actually also correspond to the multitask learning problem, uh, as well as the meta-learning problem.
Learning to learn?
Yes
More than one task for meta-learning?
Yes, or break down the original task to sub-tasks.
Meta-learning and domain adapatation?
Likely, in the domain & out of domain
Reduction?
Idea
$$
\begin{gather}
D=\bigcup D_i
\end{gather}
$$
$$
L=\Sigma L_i
$$
Union the datasets & Add up the loss functions $\to$ multi-task learning to single-task learning
Task(p for x distribution, and y distribution given x
$$T_i:={p_i(x),p_i(y|x),L_i}$$
Corresponding datasets
$$D_{i}^{tr} \quad D_i^{test}$$
In future, we will use $D_i$ as shorthand for $D_i^{tr}$
Examples of Tasks
Multi-task classification example: Students and HRs receiving emails from Warwick
Multi-label learning example: Detecting whether or not the person is wearing a hat/detecting hair color($L_i$ and $p_i(x)$ are the same, however y given x is different since there are
different binary classification tasks)
$L_i$ also vary sometimes
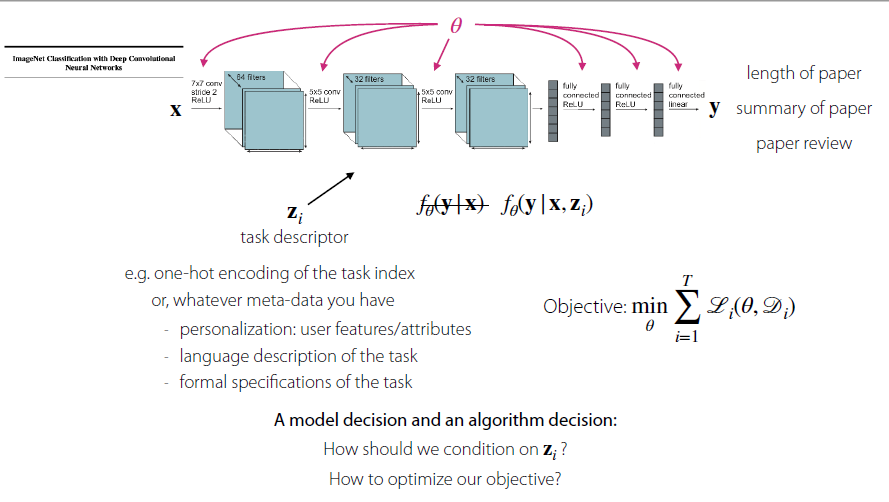
Introduction of task descriptor
To distinguish different tasks
Objective
$$\mathop{min}\limits_{\theta} \sum_{i=1}^{T}L_i(\theta,L_i)$$
Two following questions two answer
How should we condition on the task descriptor $z_i$?
How to optimize our objective?
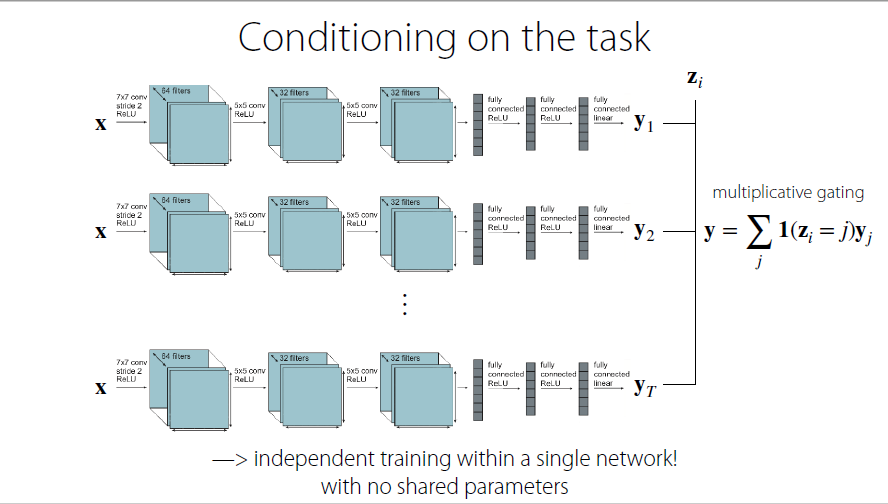
Conditioning on the task
Assuming that different tasks have same size, same dimensions
Different size → RNN or attention based model that aggregate various dimensions
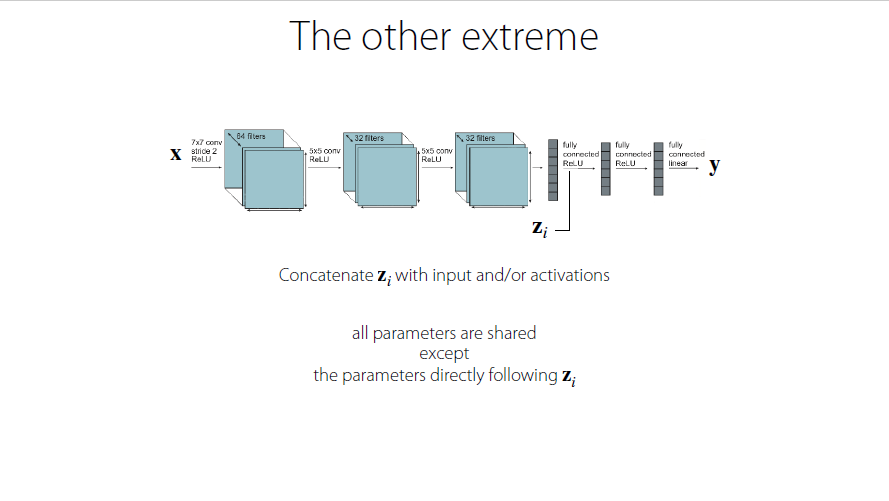
Simplest way
seperate into several neural networks with completely different weights
condition on task descriptor by pick the task corresponding to multiplicative gating
not sharing parameters trained previously
Concat $z_i$
almost all the parameters are shared
weights that are right after the $z_i$(a fully connected layer with features) are different(one-hot for example)
An Alternative View on the Multi-Task Objective
Split $\theta$, optimize $\theta^{sh}$ in union and $\theta^i$ seperately
Choosing how to condition on $z_i$ $\iff$ Choosing how & where to share parameters
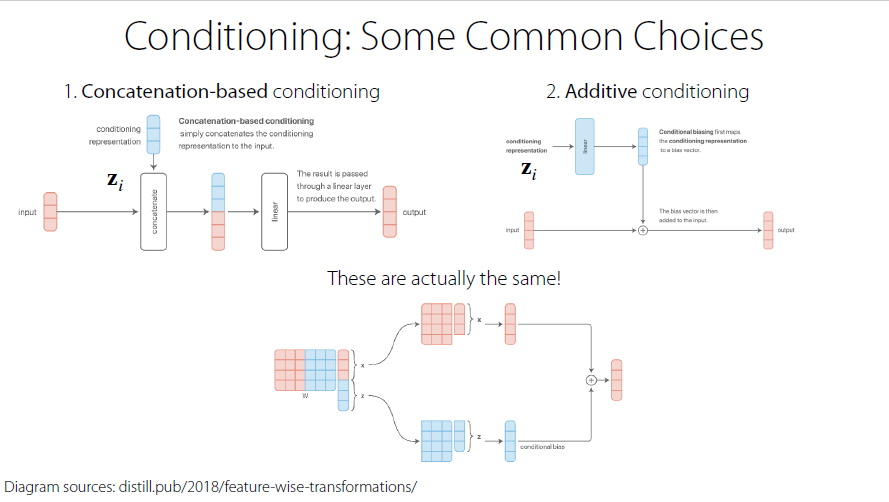
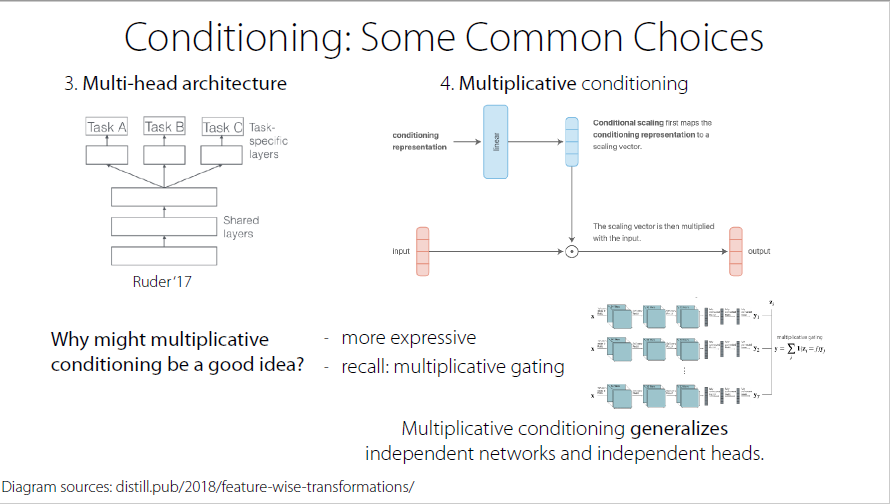
Conditioning:
Some Common Choices
Actually the same(assume as one-hot vector)
If more information is given(like the degree that two tasks are similar to each other), it can be feed to $z_i$ of the neural network. However, determining how content are shared is quite a big problem in multi-task learning.(may be figured out during the learning process rather than before training)
Multiplicative conditioning: multiply, rather than add
choose different part of the networks which should be used for various tasks → modulate different features(completely turn off features/only use some heads for one task)
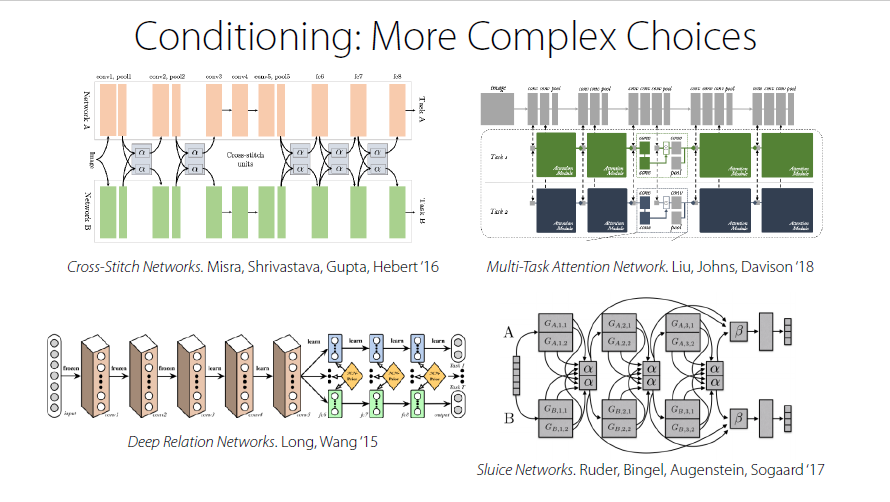
More Complex Choices
Conditioning Choices
Recall: Art, Science, Engineering architecture by Li Mu
Optimizing the objective
Basically similar to single-task learning, importance of different tasks need to be adopted manually.
However for regression problems, make sure they are on the same scale, otherwise labels have a greater magnitude → loss function having a greater scale
Challenges
Negative transfer
gradient 1 may hurts gradient 2 & one task learn much faster than another
Inverse problem: why do we expect positive transfer?
expected you don’t have a lot of data per task, & the tasks are related → features and representations learned for one task will be useful for the another task
Combine two different neural networks with same structure?
Create a task selector naively → try to learn a single network
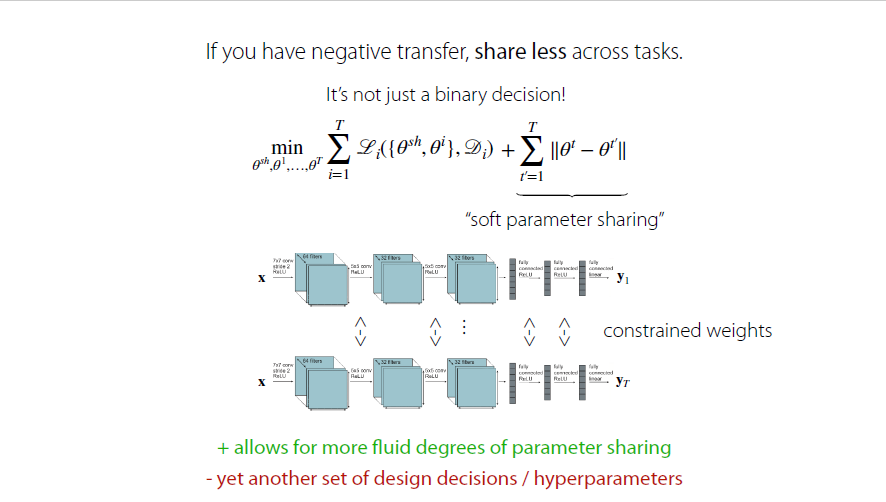
soft parameter sharing
Idea: encourage the task specific parameters to be simliar to one another
Overfitting
Case study
User Engagement & User Satisfication
Framework Set-Up
The Ranking Problem
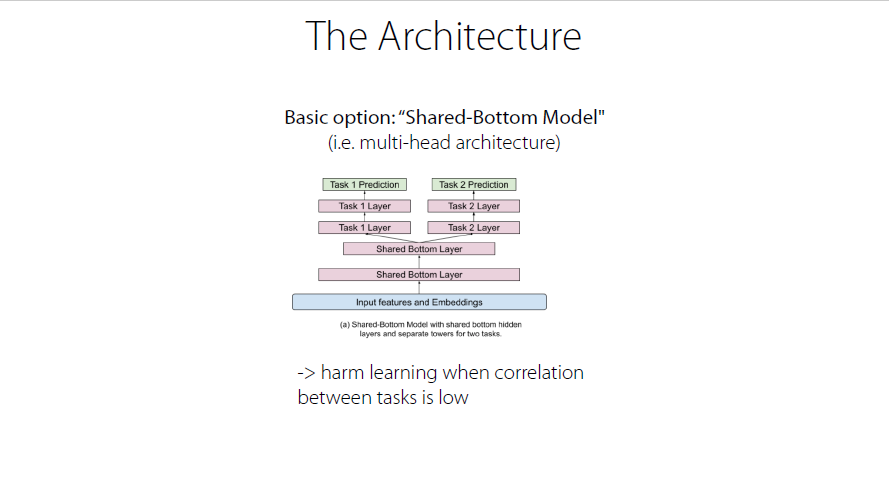
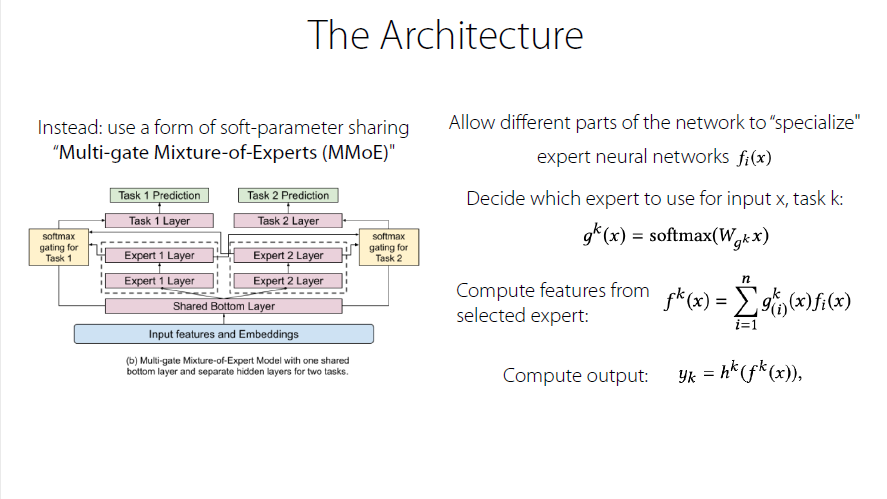
The Architecture
baseline
Decide the experts/expert used
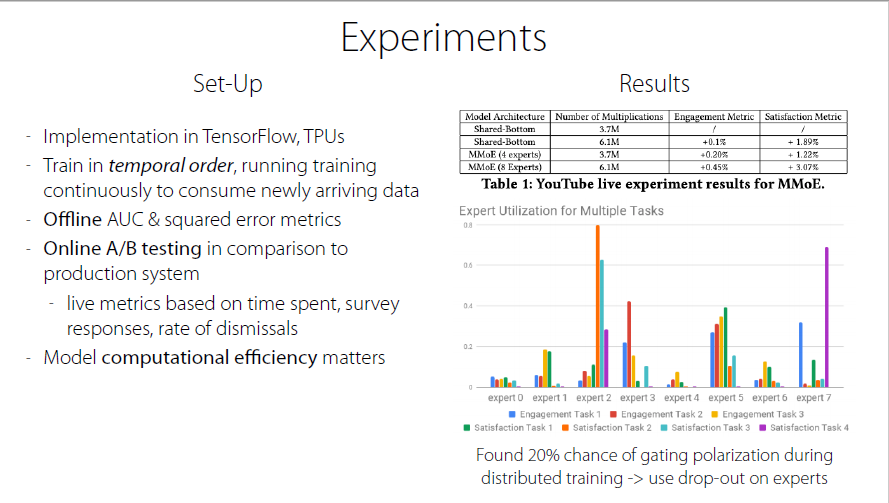
Experiments
Experts meet one or several tasks
polarization → using one expert or no expert at all
Meta-Learning Basics
Two ways to view meta-learning algorithms
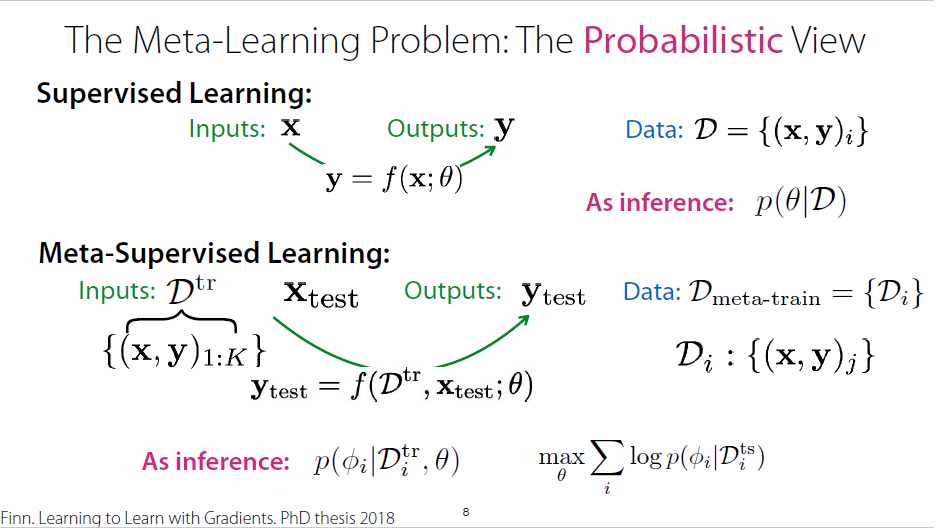
Problem definitions(Probabilistic view)
Ideas: can we incorporate additional data?
Tips: it don’t need to be image classification problem
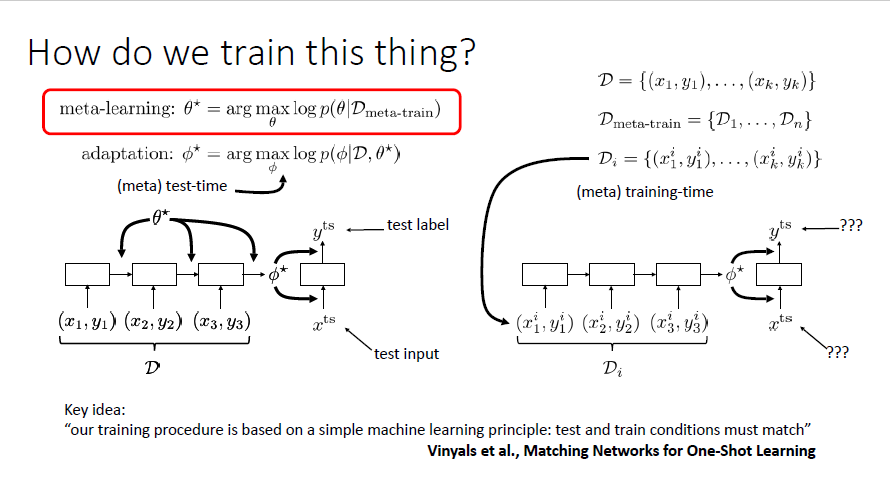
The meta-learning problem
assume that $\phi$ and $D_{meta-train}$ are conditionally independent conditioned on $\theta$
(if the parameters from meta-training dataset is given, new parameters and meta-training dataset are independent)
so that the meta-training problem can be understood as
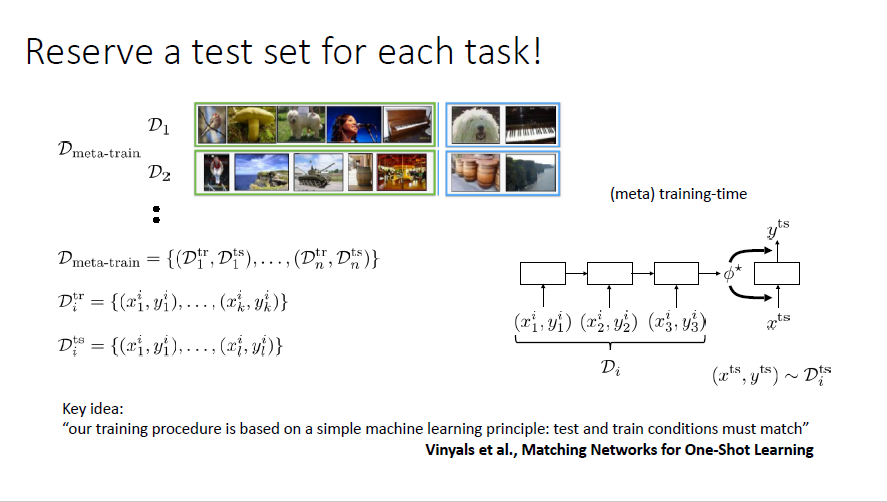
split other datasets for meta-training and adapt to any ML problem
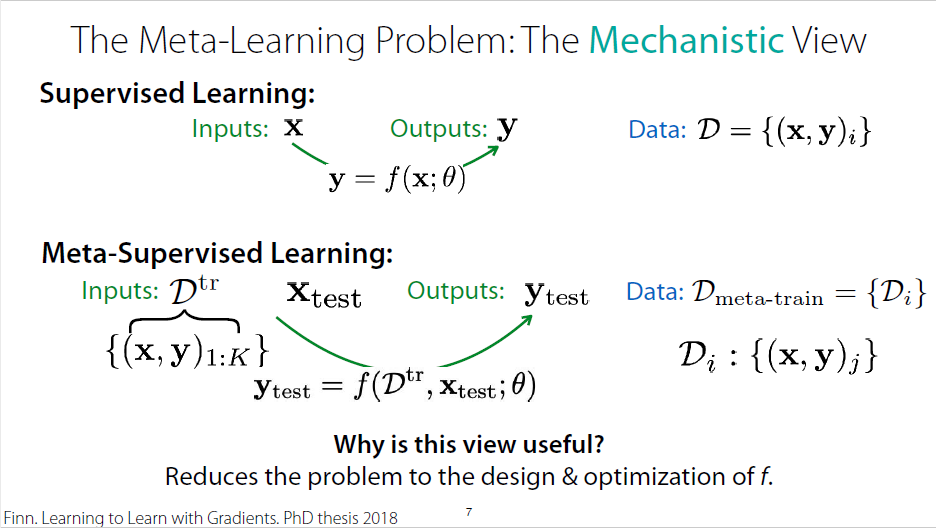
The Meta-Learning Problem: The Mechanistic View
The Meta-Learning Problem: The Probabilistic View
Assumption: the training task and new task are from the same distribution?
How to design a meta-learning algorithm
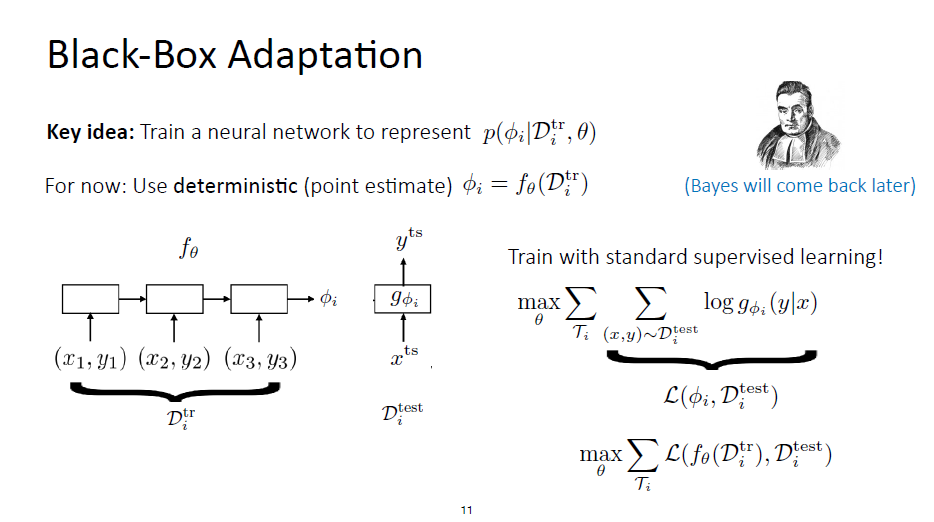
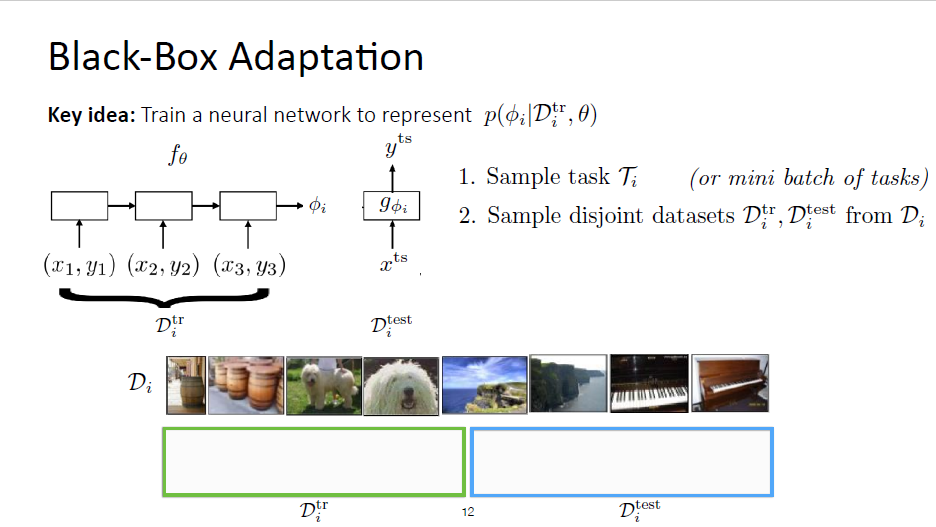
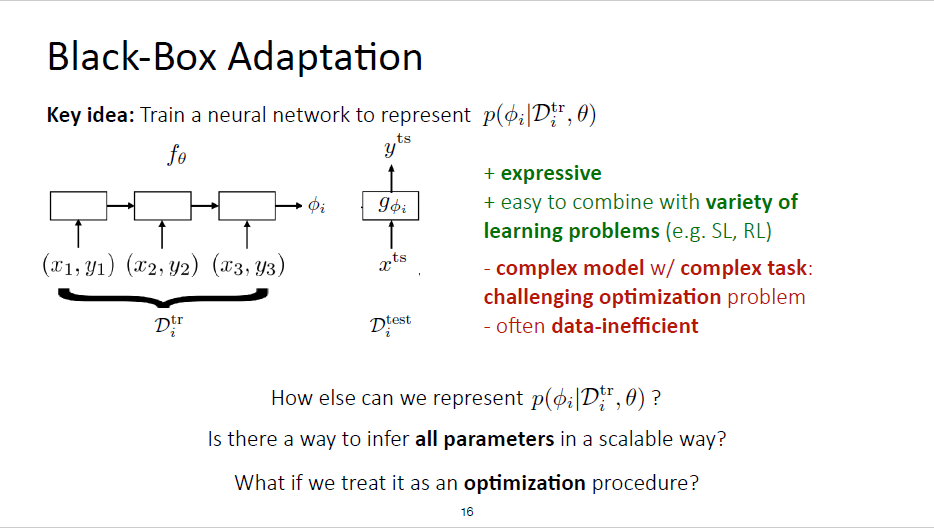
Black-Box Adaption
Overview
$f _{\theta}$ : sequential fashion/one batch
Train with standard supervised learning: maximize the probability of the labels under the distribution that $G$ is producing
在meta-learning process中,$\theta$被learned,$\phi$则可以被看作activations/tensor rather than actual parameters
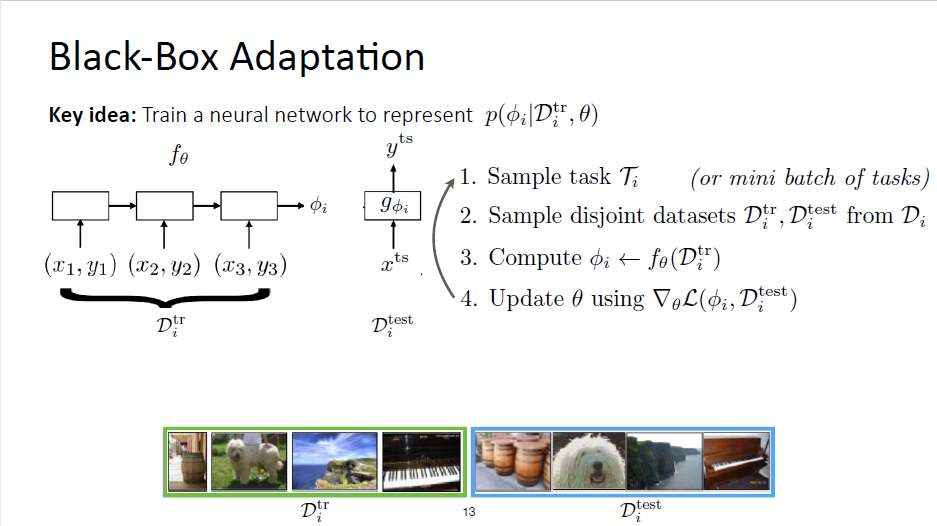
Meta-Training Part
randomly split
repeat this iteratively using your favorite gradient descent optimizer
all the $\theta$ are meta paramters and then $\phi$ is considered as the task-specific parameters
we update $\theta$ and do not update $\phi$ since it’s basically dynamically computed at every iteration
it has to go through $\phi$ in order to cumpute the gradient $\nabla_{\theta}L(\phi_i,D_i^{test})$ for $\theta$
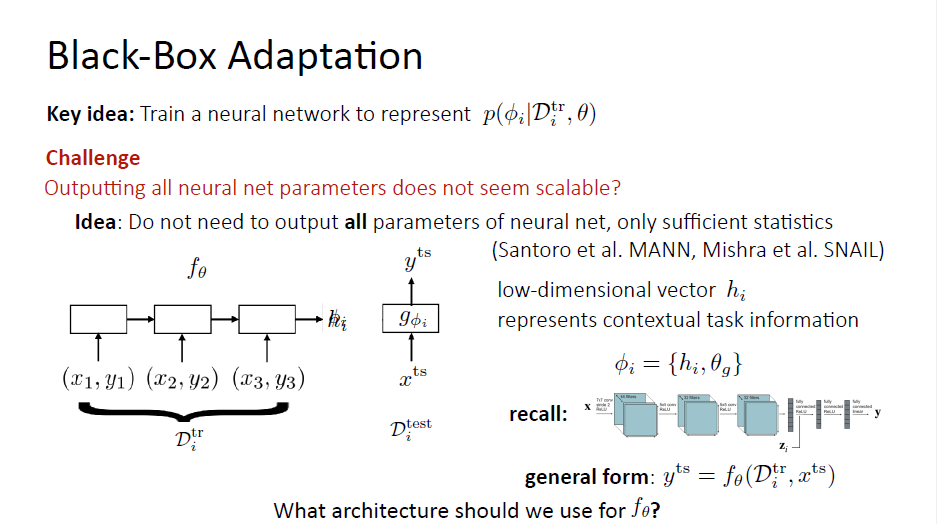
Challenge
If $\phi$ is litearlly representing all the parameters of another neural network, it may not be that scalable to actually ouput all of those neural network parameters because neural networks are very large.
sufficient statistics $h_i$(lower dimensional vector)(similar to the hidden state of LSTM)
$$\phi_i={h_i,\theta_{g}}$$
general form
$$y^{ts}=f_{\theta}(D_i^{tr},x^{ts})$$
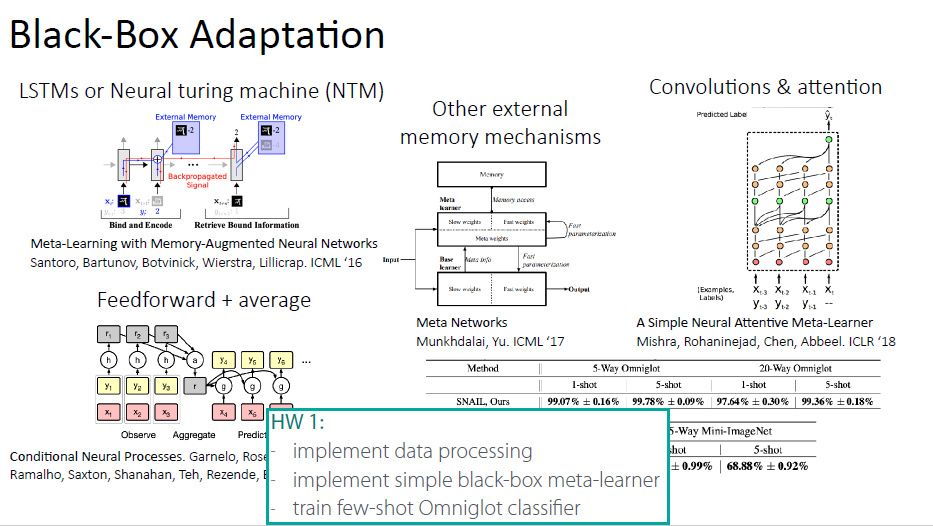
Architecture
Pros and Cons
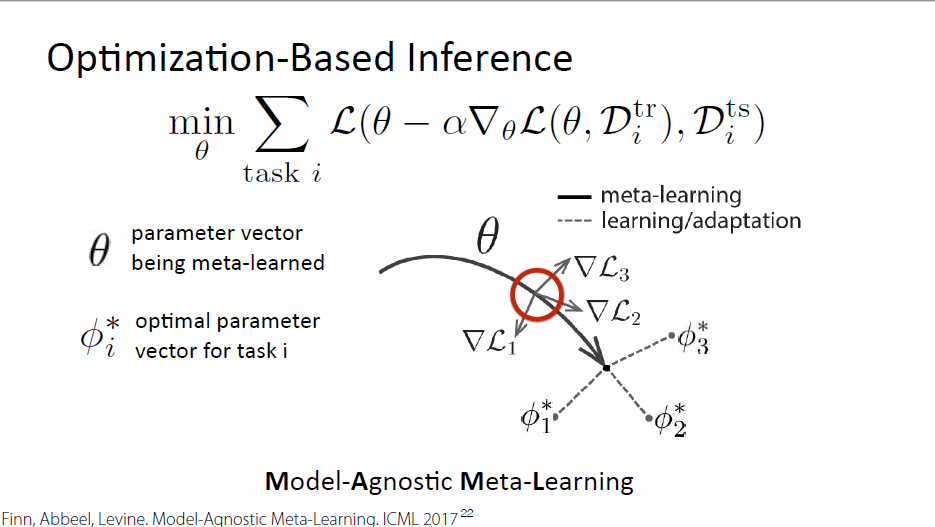
Optimization-Based Inference
Inference problem → optimization procedure
$$\mathop{max}\limits_{\phi_{i}}\log p(D_i^{tr}|\phi_i)+\log p(\phi_{i}|\theta) $$
break down the meta-training problem to two terms
maximizing the likelihood of training data given task-specific parameters
optimizing the likelihood of task-specific parameters under meta parameters
It’s actually a whole space of optimums rather than single optimum
meta-learning + multitask learning
Formula
Single Inner Gradient Steps
$d$ as total derivative, $\nabla$ as partial derivative, $u$ as update rule, and $D^{test}$ for $D_i^{test}$
$$\phi=u(\theta,D^{tr})$$
$$\mathop{min}\limits_{\theta}L(\phi,D^{test})=\mathop{min}\limits_{\theta}L(u(\theta,D^{tr}),D^{test})$$
$$\frac{d}{d\theta}L(\phi,D^{test})$$
$$
Let \quad U(\theta,D^{tr})=\theta -\alpha d_{\theta}L(\theta,D^{tr})
$$
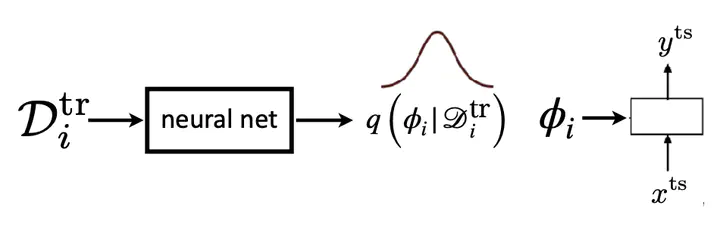 architecture
architecture