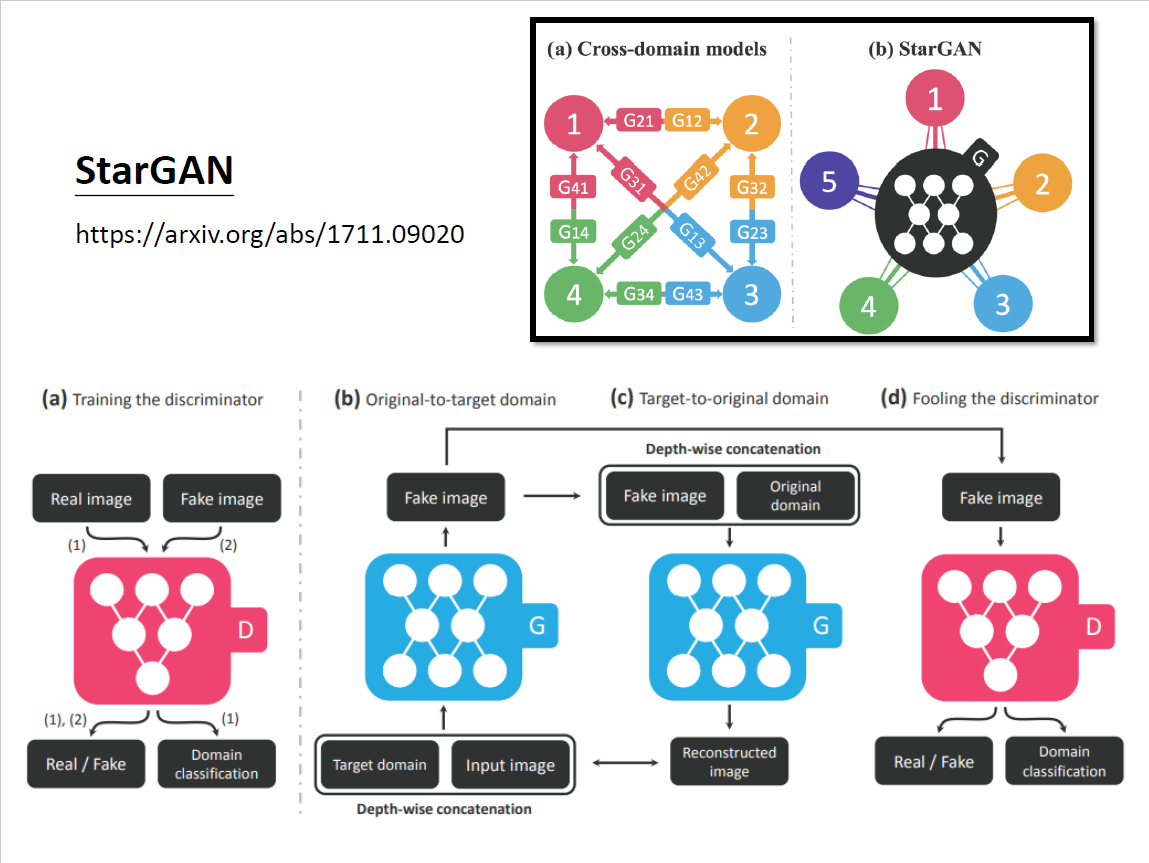
 architecture
architecture
参考资料
基本概念介绍
Tips:
- 输入distribution一般选择正态分布
- 第一次的generator是随机生成的,基本属于完全混乱的状态
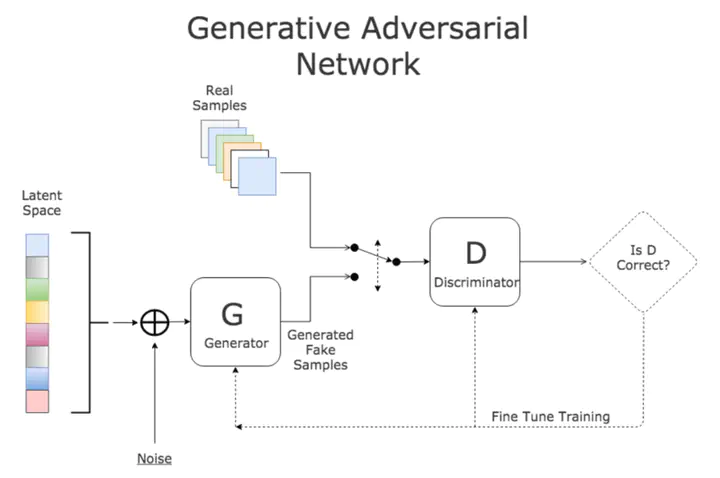
- 整体网络由NN Generator和Discriminator组合构成,输入是向量,输出是0-1的分数,越高越好。
- 通过styleGAN可以实现图片内插(类似动画补间效果)
理论介绍与WGAN
Loss Function:
$$ G^*=\mathop{\arg\min}\limits_G Div(P_G,P_{data}) $$
Divergence即衡量两个distribution之间的某种距离,越小表示越相似
目的:找到一组generator的参数
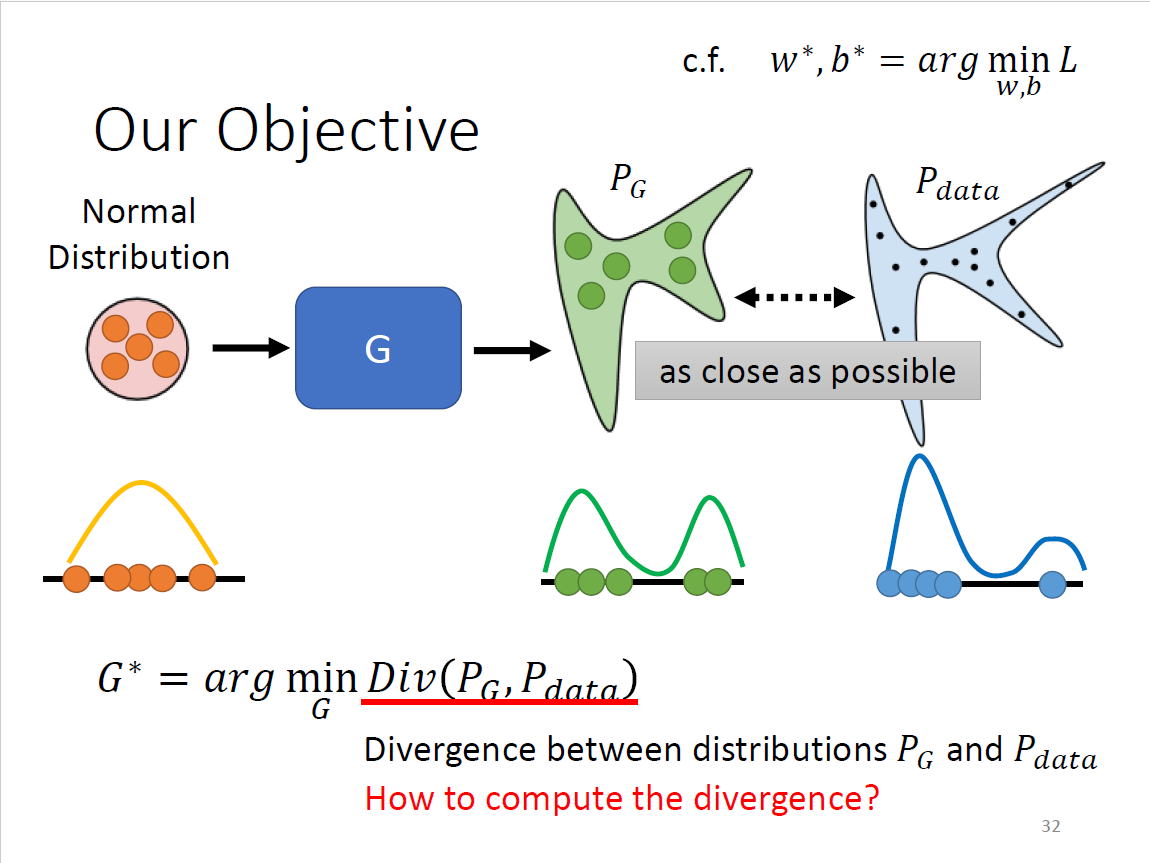
Divergence?
- KL、GS无法使用,因为要做非常复杂的积分
- GAN可以突破不知道如何计算divergence的限制
- 只要可以sample出来,就可以计算divergence
- generator的sample是从(Gaussian)分布中拿向量,也即输入,而非输出
- 不知道完整的formulation→估测divergence

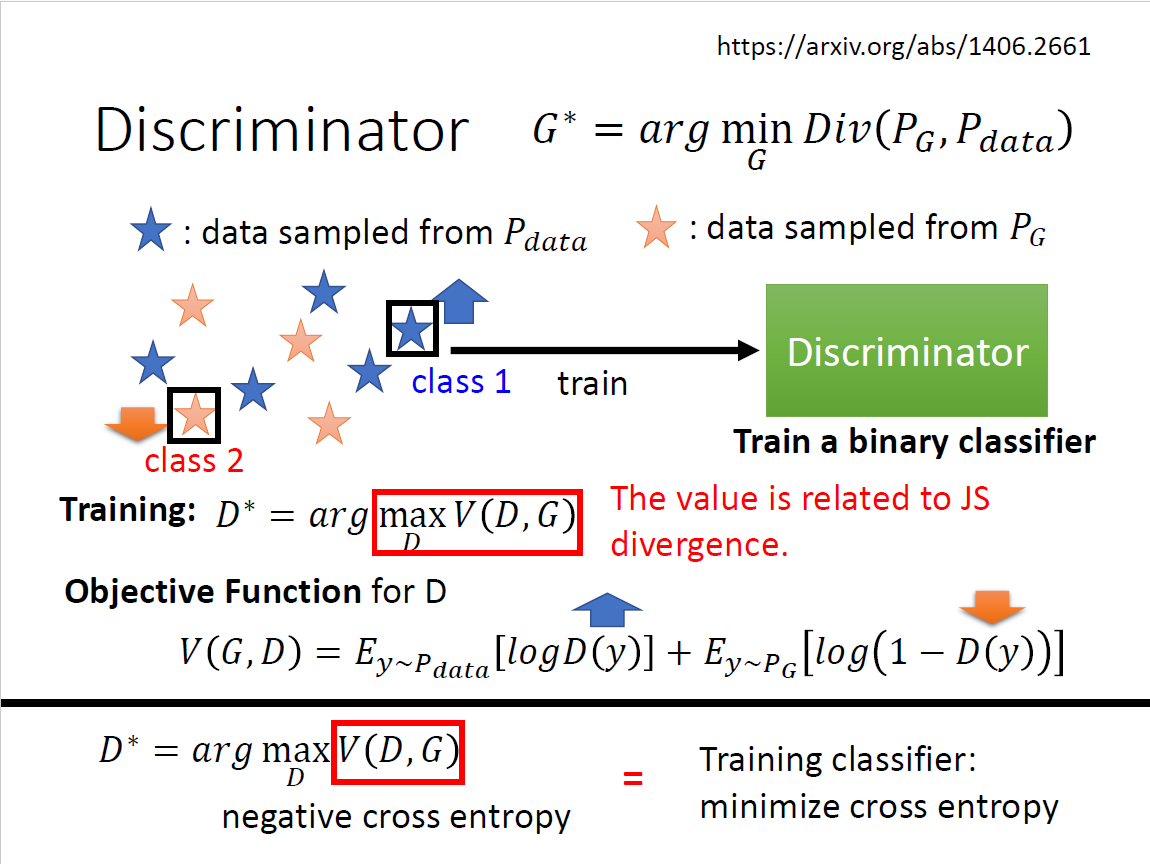
Discriminator
Training
$$ D^*=\mathop{\arg\max}\limits_D V(D,G) $$
跟JS Divergence有关 可以理解为最小化交叉熵损失
Objective Function
$$ V(G,D)=E_{y\sim P_{data}}[\log D(y)]+E_{y\sim P_{G}}[\log (1-D(y))] $$
优化方向:$D(y)$越大越好 即负向二分类交叉熵损失 从Binary Classifier中来
直观理解
在divergence较小的时候,优化问题所能达到的max值较小;而当两种图片很容易分别的时候,优化效果较好,也能达到更大的数值
Generator
maximum objective value $\mathop{\max}\limits_D V(D,G)$是与JS divergence直接相关的,此处可以做替换。 $$\begin{gather} G^*=\mathop{\arg\min}\limits_G Div(P_G,P_{data})\ Div(P_G,P_{data})=\mathop{\max}\limits_D V(D,G) \end{gather}$$
不难得出 $$ G^*=\mathop{\arg\min}\limits_{G}\mathop{\max}\limits_D V(G,D) $$
generator和discriminator互相欺骗的过程可以通过$\mathop{\arg\min}\mathop{\max}$来直观理解
Training
JS divergence
多数情况下,$P_G$和$P_{data}$重叠的部分特别少(高维空间的低维manifold)
- 二维空间两条直线(曲线)相交的概率?比较小
- 取样过程中如果sample不够多可能重复的也不会显示出来
两个没有重叠的分布算出来就一定是$\log 2$
- 虽然对于generator来说,效果右图>中图>左图,但由于loss function无从体现,所以并不存在这样的优化趋势和方向,也就无从变好
- binary classifier永远可以达成100%的accuracy,因而doesn’t make sense


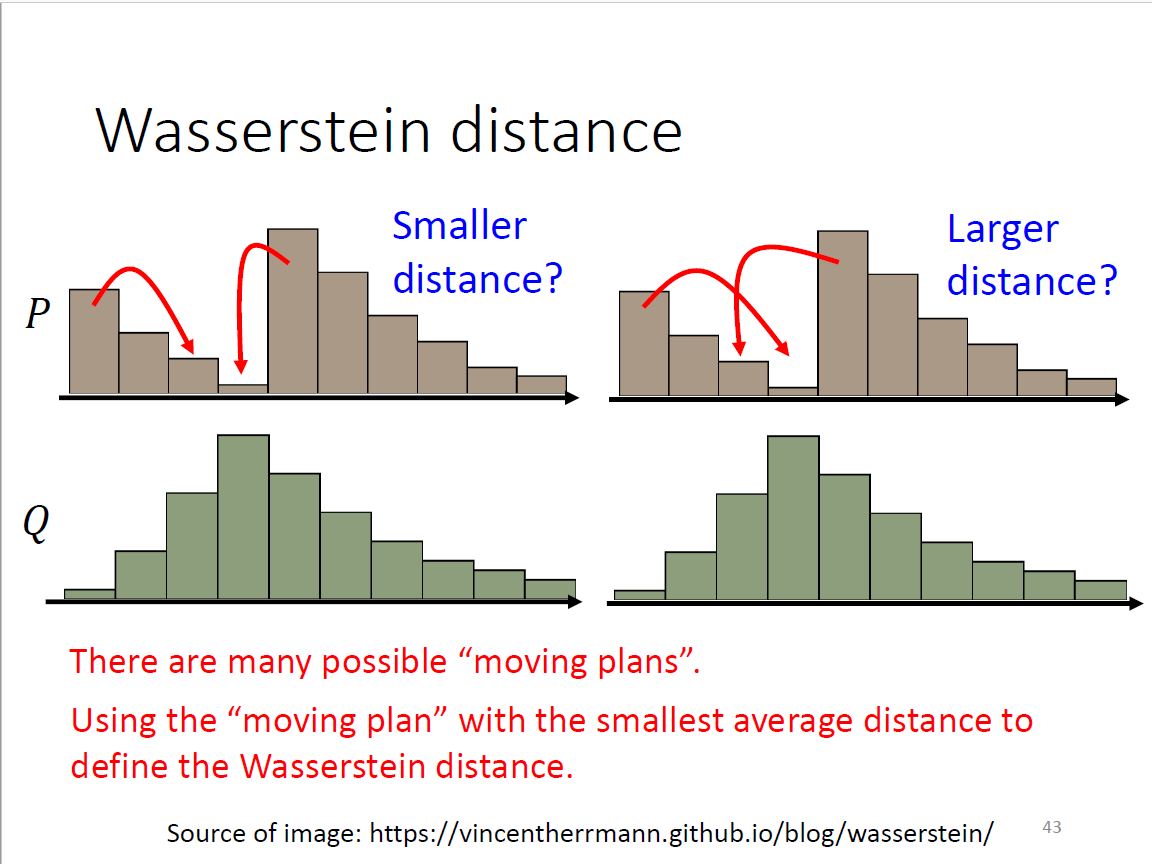
Wasserstein distance
P和Q各是一堆土,求所需移动的平均距离,因而也叫earth mover distance。 问题:moving plan非常多,难以计算所有种类
补充定义为穷举所有的方式,让moving distance最小的方案作为输入(非常复杂,需要先解一个optimization问题) 逐步演化例子:感光细胞→完整的眼睛 W distance优势在于产生了优化的趋势,每个step都有微小的变化
WGAN
- D需要足够平滑,要求discriminator不能变化太剧烈
- 若x是从data出来的,discriminator的output越大越好,而如果x是来自generator,discriminator的output越小越好
- 下图中优化得出的最大值即为Wasserstein distance
- Original WGAN→Weight:强行限制$w$在某个区间
- Improved WGAN→Gradient Penalty:两个sample的浓度问题
- Spectral Normalization:任何地方梯度严格小于1

生成式效能评估与条件式生成
Challenges
Generator和Discriminator亦敌亦友,互相进步的关系,一个停滞另一个也会
More Tips
Tips from Soumith Tips in DCGAN: Guideline for network architecture design for image generation Improved techniques for training GANs Tips from BigGAN
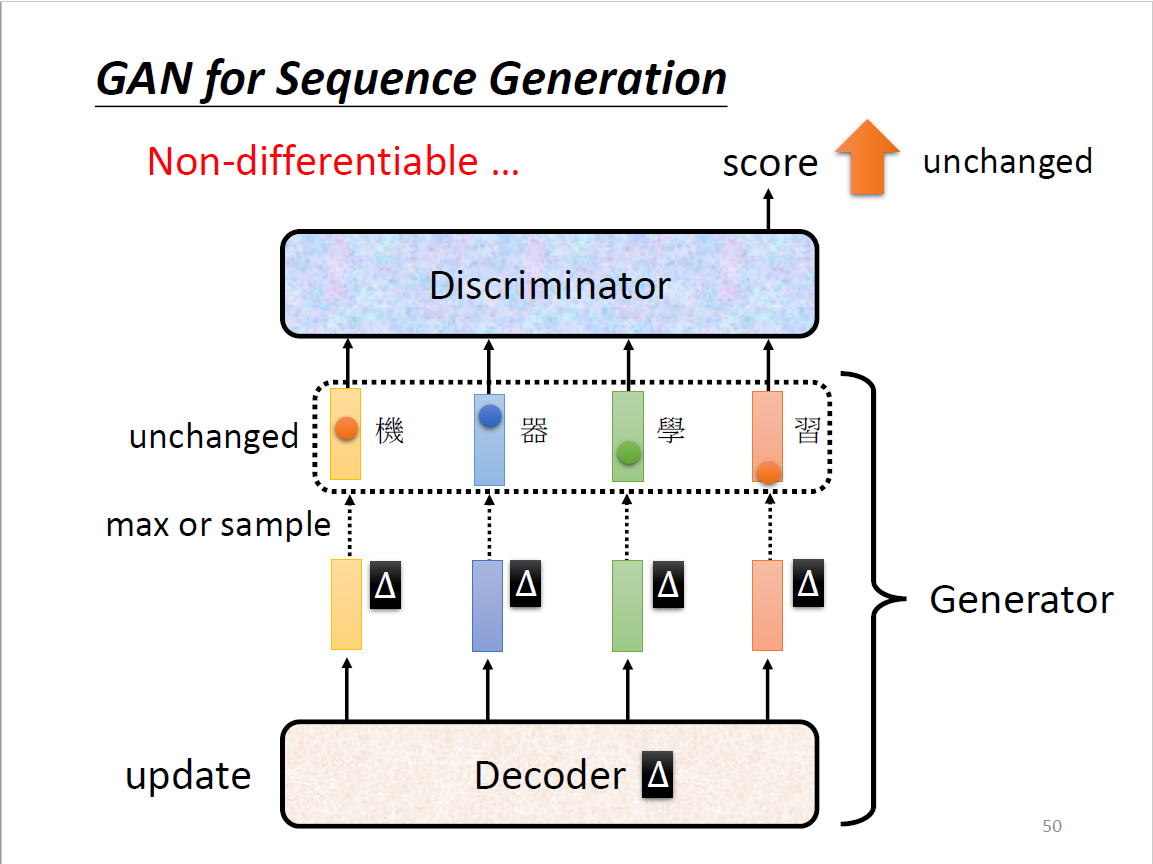
GAN for Sequence Generation
困难在于生成文字序列
- Sequence to sequence model从decoder变成了generator
- 使用gradient descent训练的时候,decoder有变化,distribution会有变化
- token:中文方块字、英文字母、英文词(看每次生成什么)
- 当Decoder有一点变化的时候,max→Discriminator的输出分数不变
- 最大分数的token依然保持最大的分数
- 因而没有积分,无法做gradient descent
不可导
GAN+Reinforcement Learning? 都很难train 加在一起会爆炸 需要做pre-train Google paper: Training language GANs from Scratch 爆调hyperparameter,不做pre-train
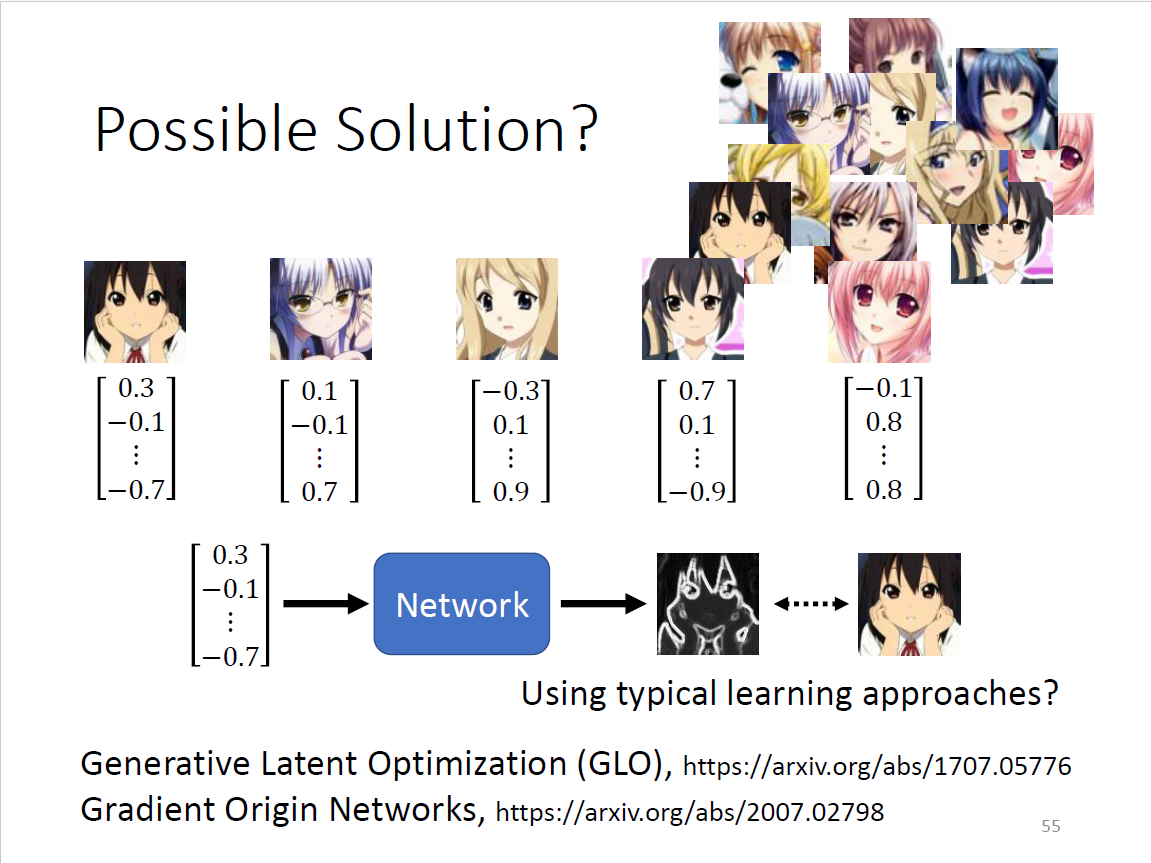
Possible Solution?
gaussian distribution生成向量,一对一supervised learning爆训
Quality of Image
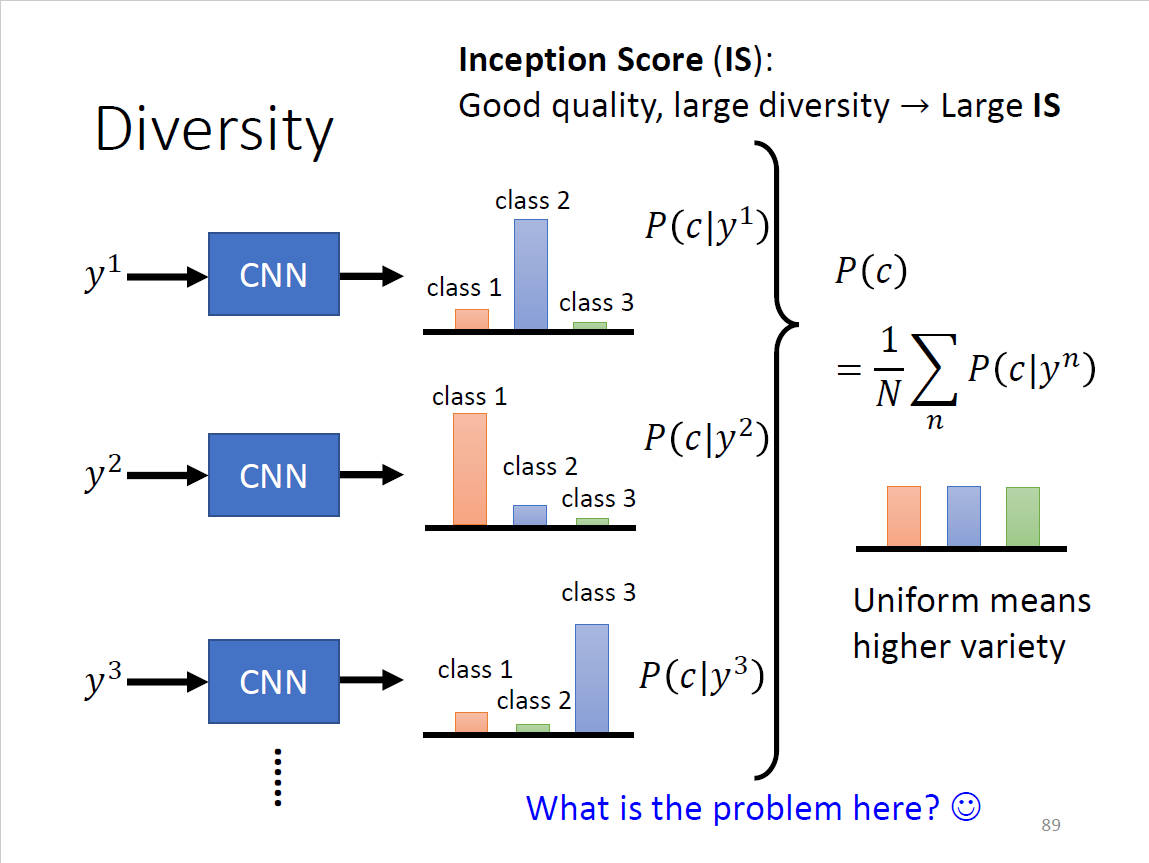
如何评估?扔进影像分类系统,输出几率分布,越集中越好,避免平坦/平均分布

Diversity
Mode Collapse
- 同一张脸越来越多,因为是discriminator的盲点,generator抓到了这个盲点
- 没有彻底的解决方案,但是可以在mode collapse之前停下
Mode Dropping
- 更难被辨识,因为基本相近,但是分布的多样性不够
- t周期整体偏白,t+1周期整体偏黄
扔到图片分类系统
- diversity跟quality互斥?一堆图片和一张图片作为主体
- diversity有一个先集中再取均值后变分散的过程
- Inception Score: good quality,large diversity


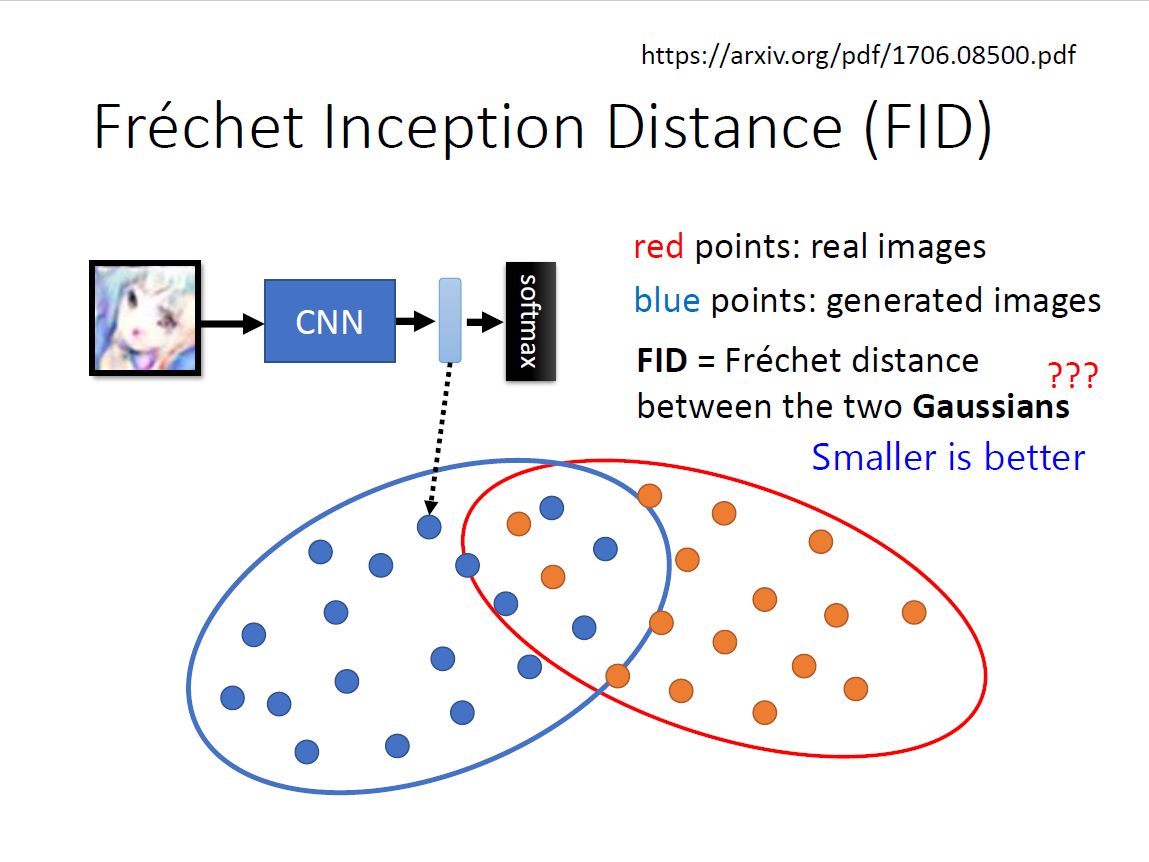
$Fr\acute{e}chet \quad Inception \quad Distance(FID)$
- 不取类别,相反,保留进入softmax之前的高维向量
- 假设都为Gaussian distribution,计算FID(越小越好)
- 需要大量sample,对算力有要求
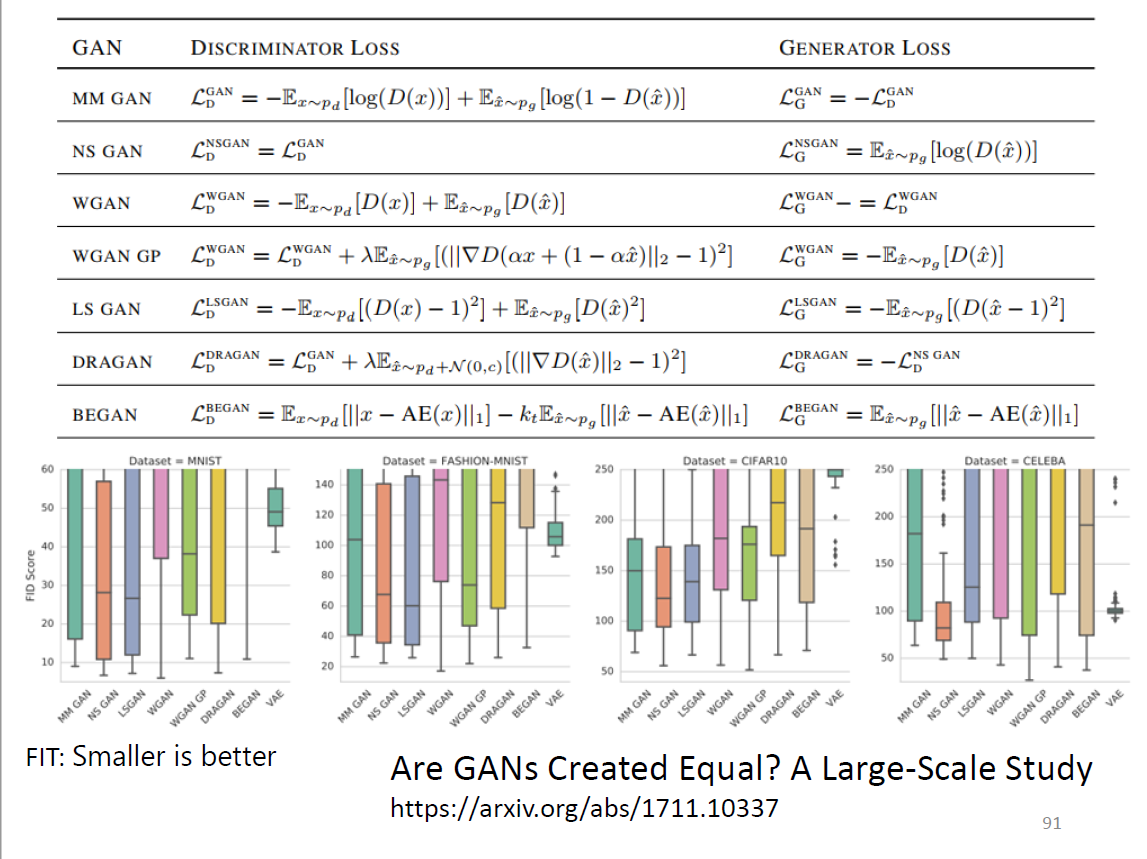
- GAN比VAE结果好很多,但随机性也较大(random seed),不如VAE稳定
Memory GAN
- 目的:我们想要什么?新的图片而非原有图片,如翻转或者直接从data中sample
- 困境:generator通过上述方式得到的数据FID会非常小,扔到图片分类系统效果好
- evaluation其实非常困难,评估generator的方式很多,也比较复杂

Conditional Generation
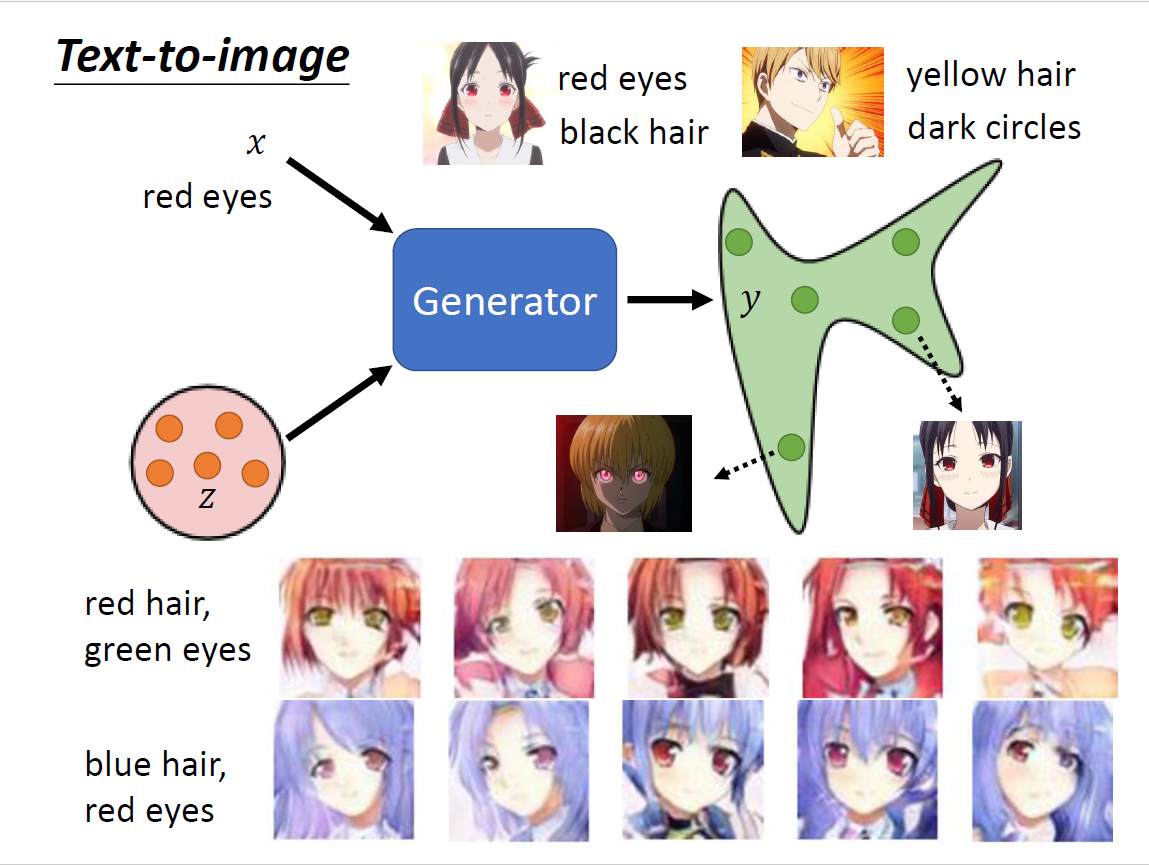
Text-to-image
- 文字对图片的生成(RNN/Transformer),实际上可以理解为supervised learning
- sample到不一样的z会有不同的输出,但是都满足x的输入
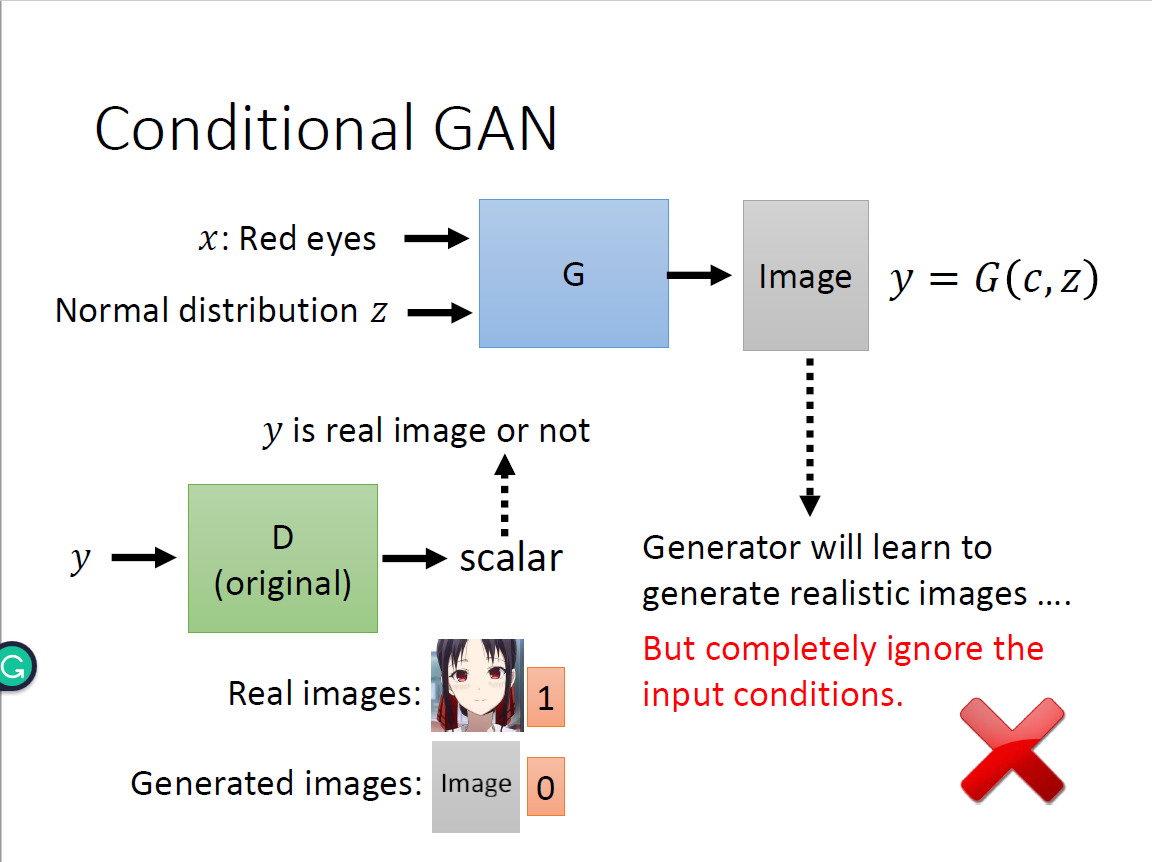
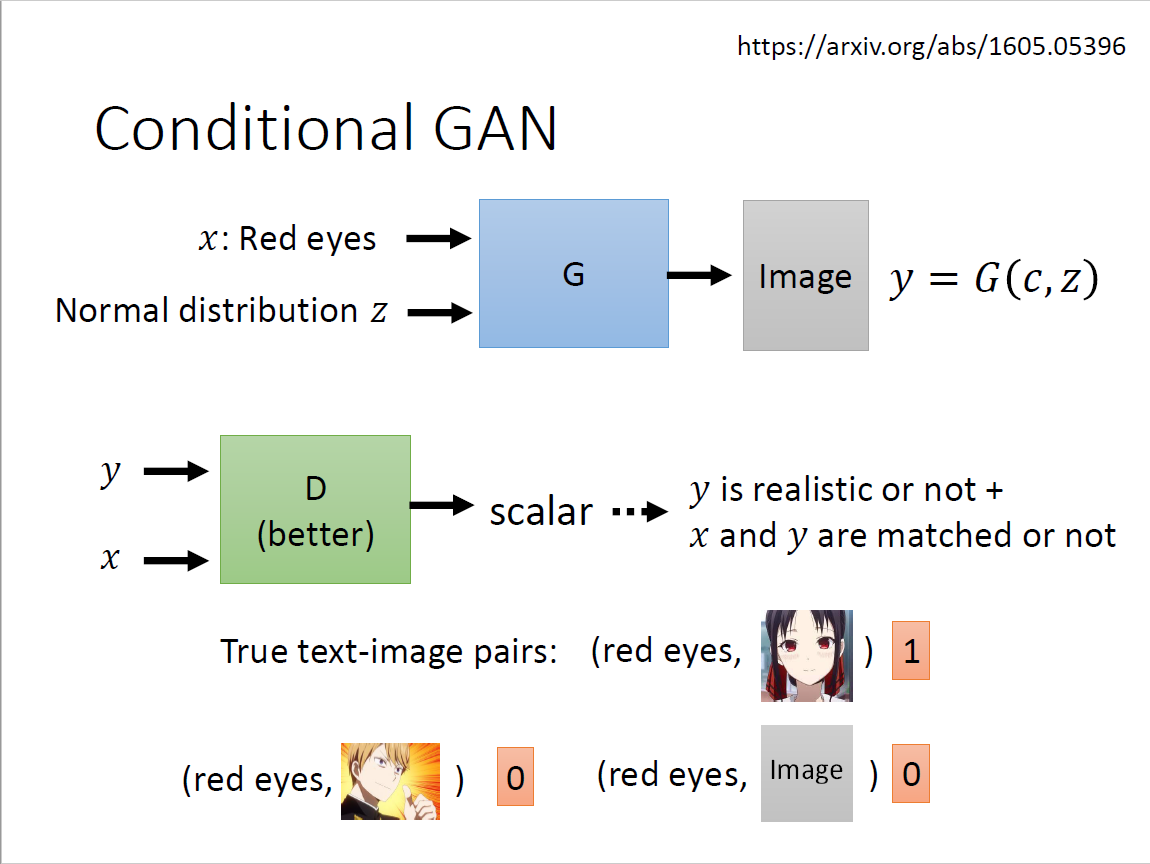
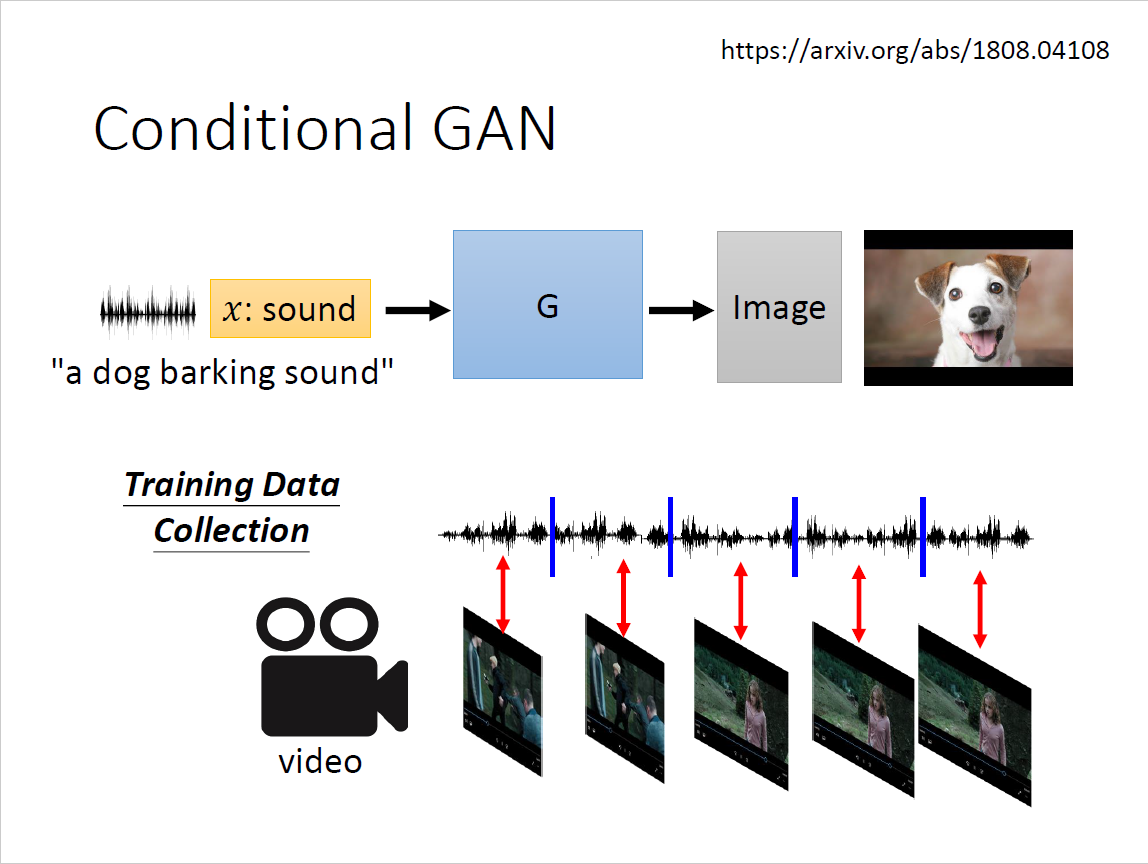
Conditional GAN
$$ y=G(x,z) $$
$$ s=D(y) $$
问题在于generator会产生更倾向于骗过discriminator的图片输出(loss function优化方向),但是会完全忽略输入也即x和z。 解决方案:discriminator既有y作为输入也有conditional x作为输入
- 图片要跟文字的输入相匹配,因而需要引入paired data
- 匹配的时候给1分,不匹配的时候给0分
- 但仅这样训练不够,需要拿已有资料作假乱配,告诉它是错的
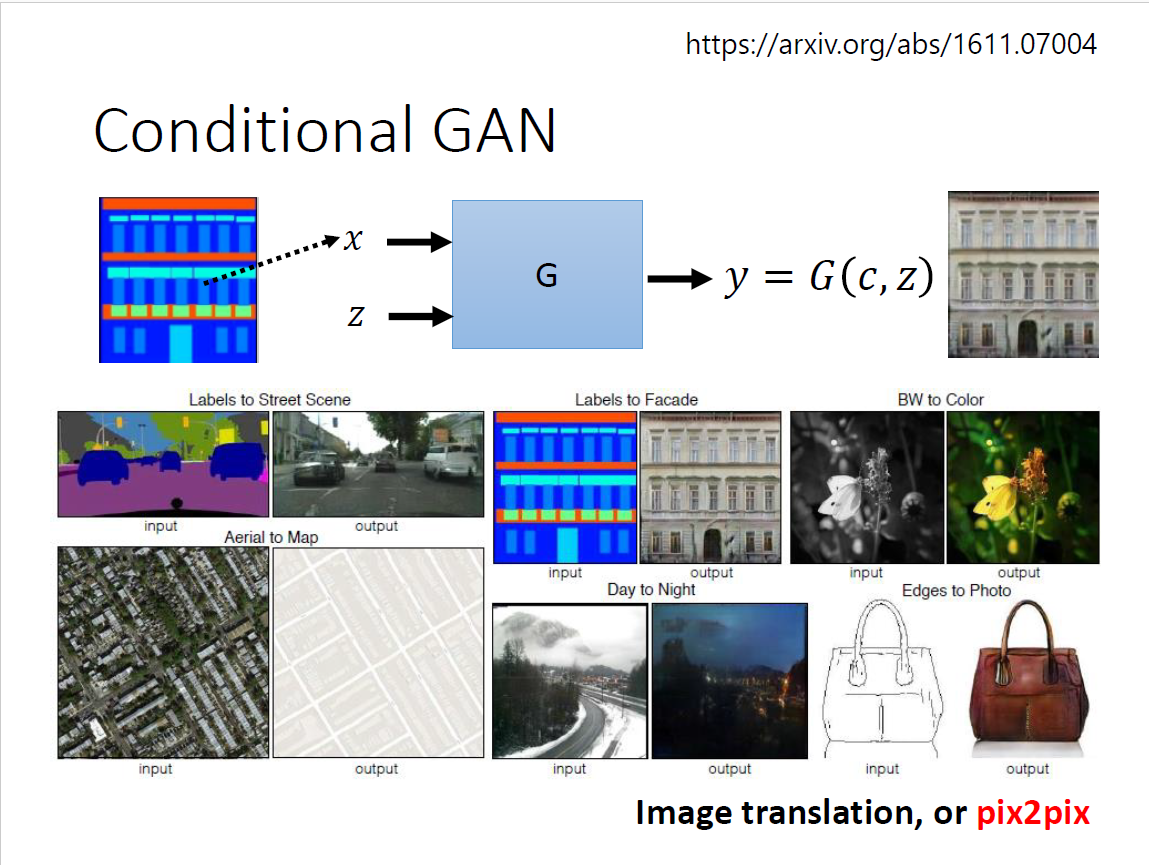
应用
处理方法: 把文字的部分用文字取代掉,依然可以使用supervised learning? 问题:
- 生成的图像非常的模糊
- 同样的输入,对应不同的输出
- 类比小精灵分类,同时向左转向右转
- 把不同的可能平均出来,得到一个模糊的结果
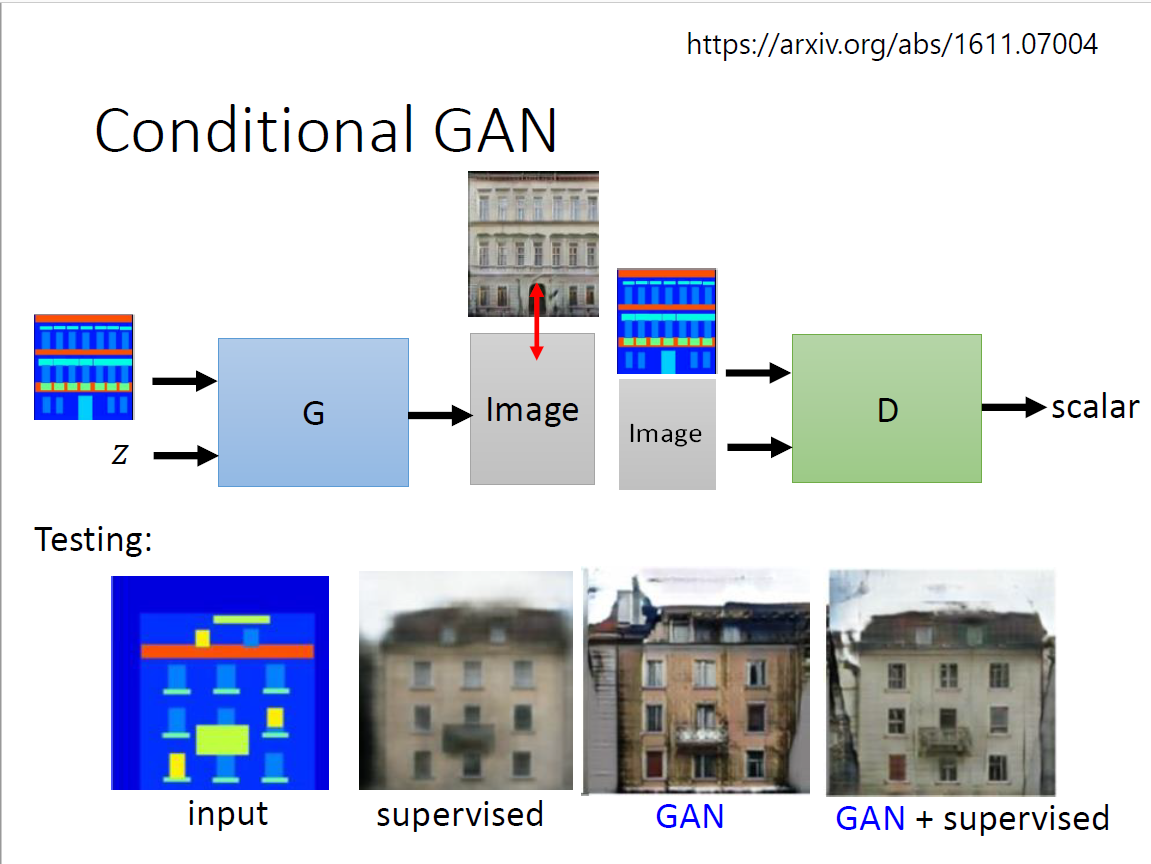
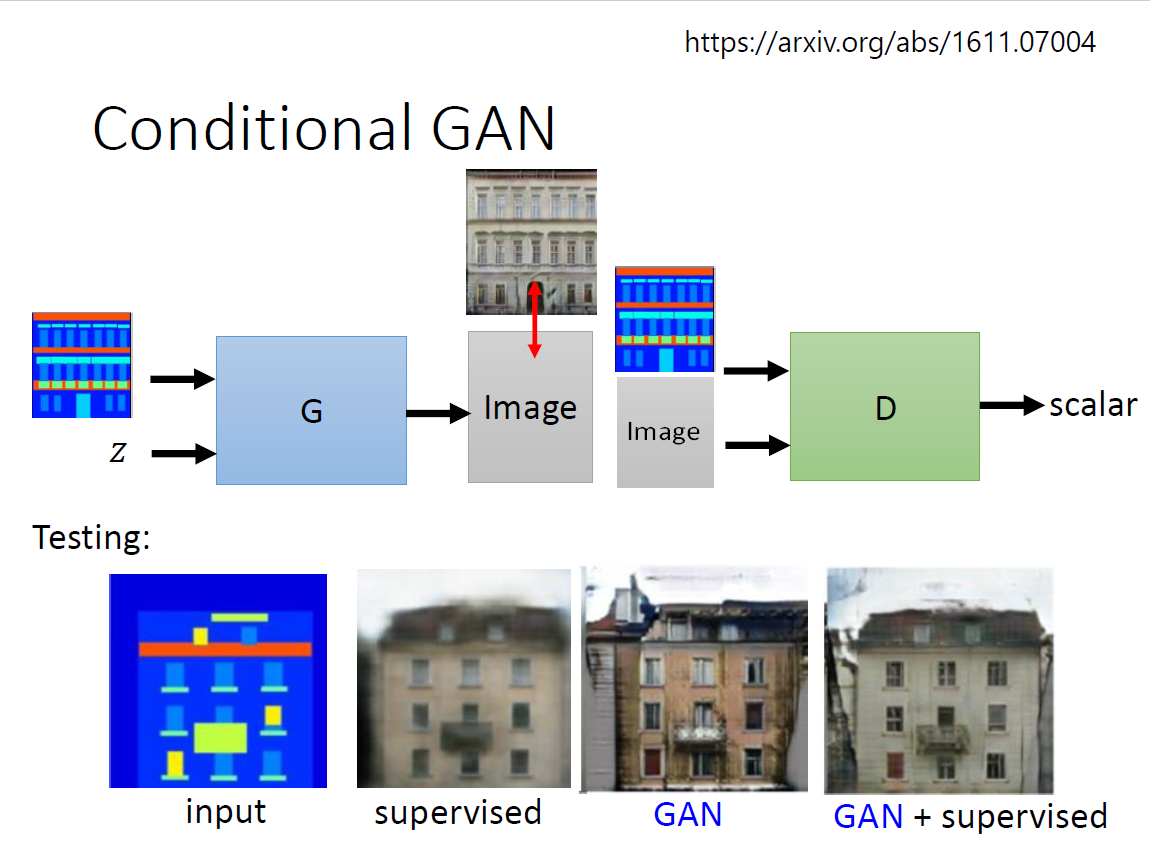
方法:添加一个condition(跟supervised相比想象力会很丰富)
折中方式:同时使用 神奇应用


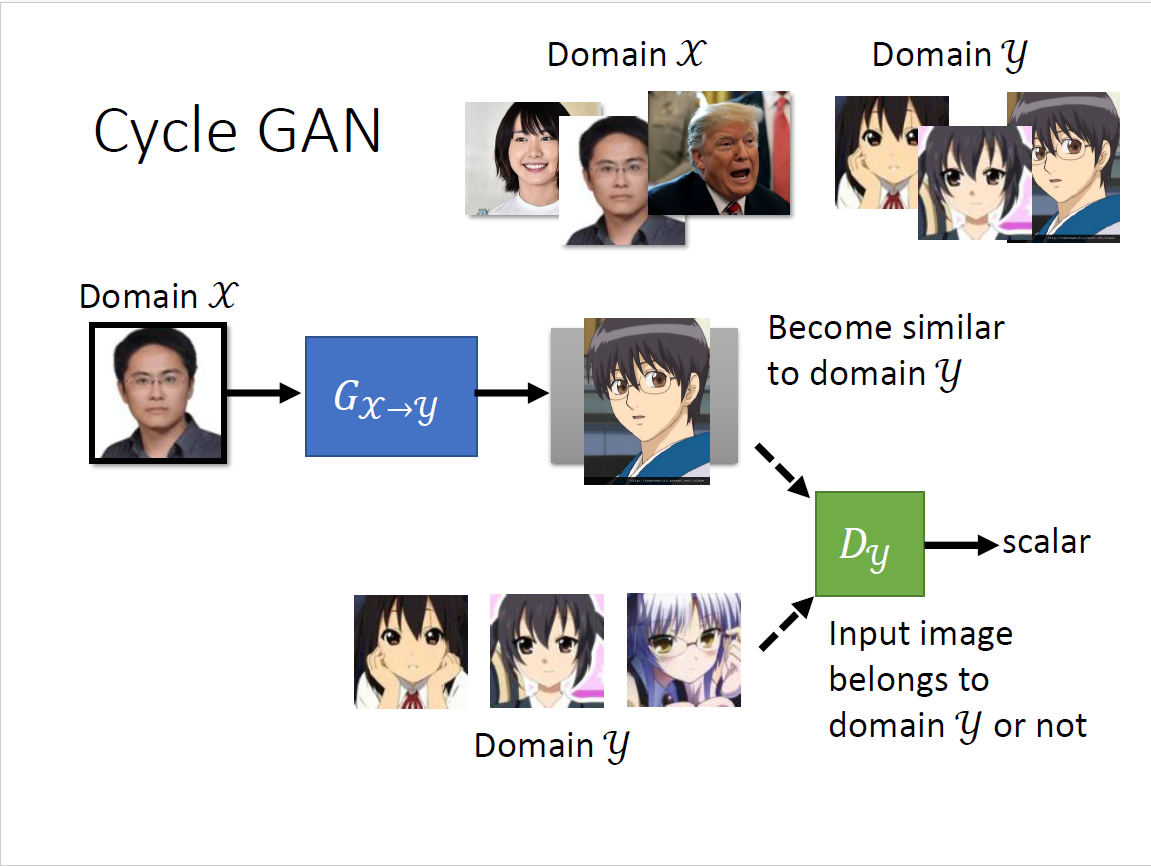
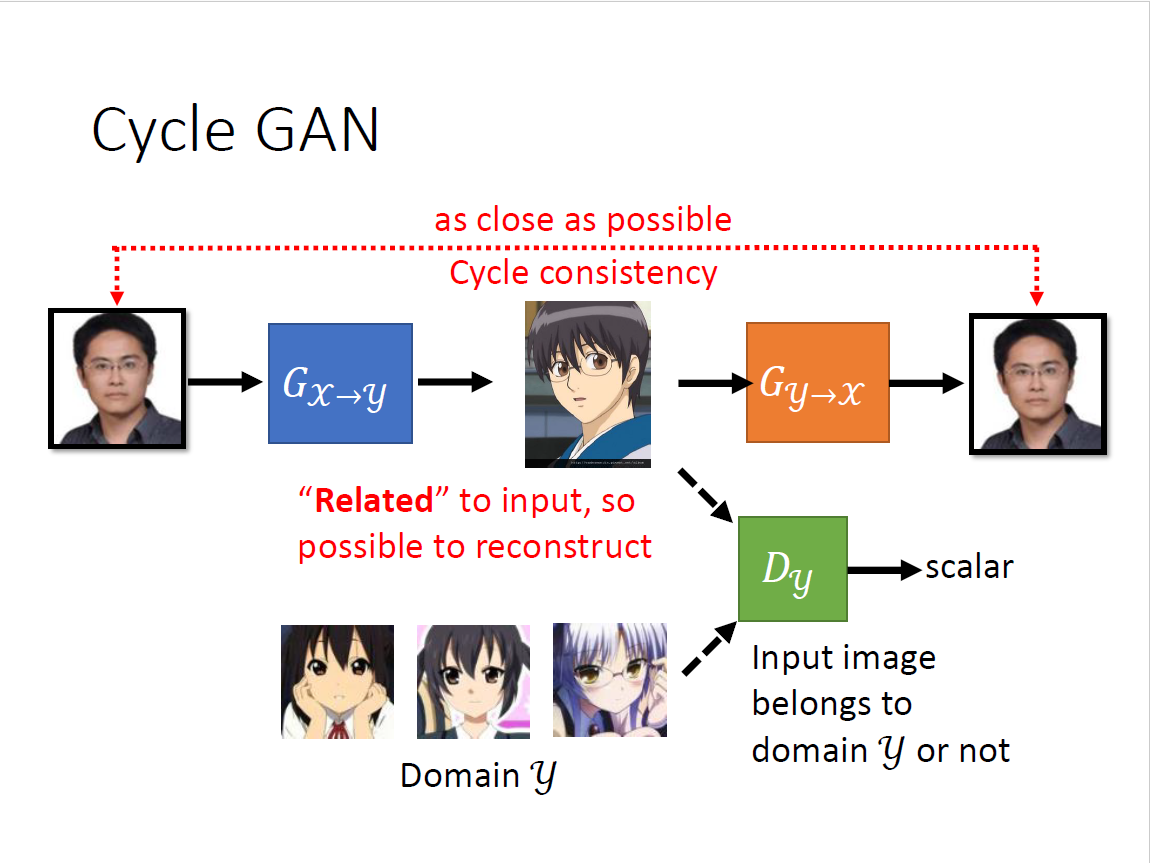
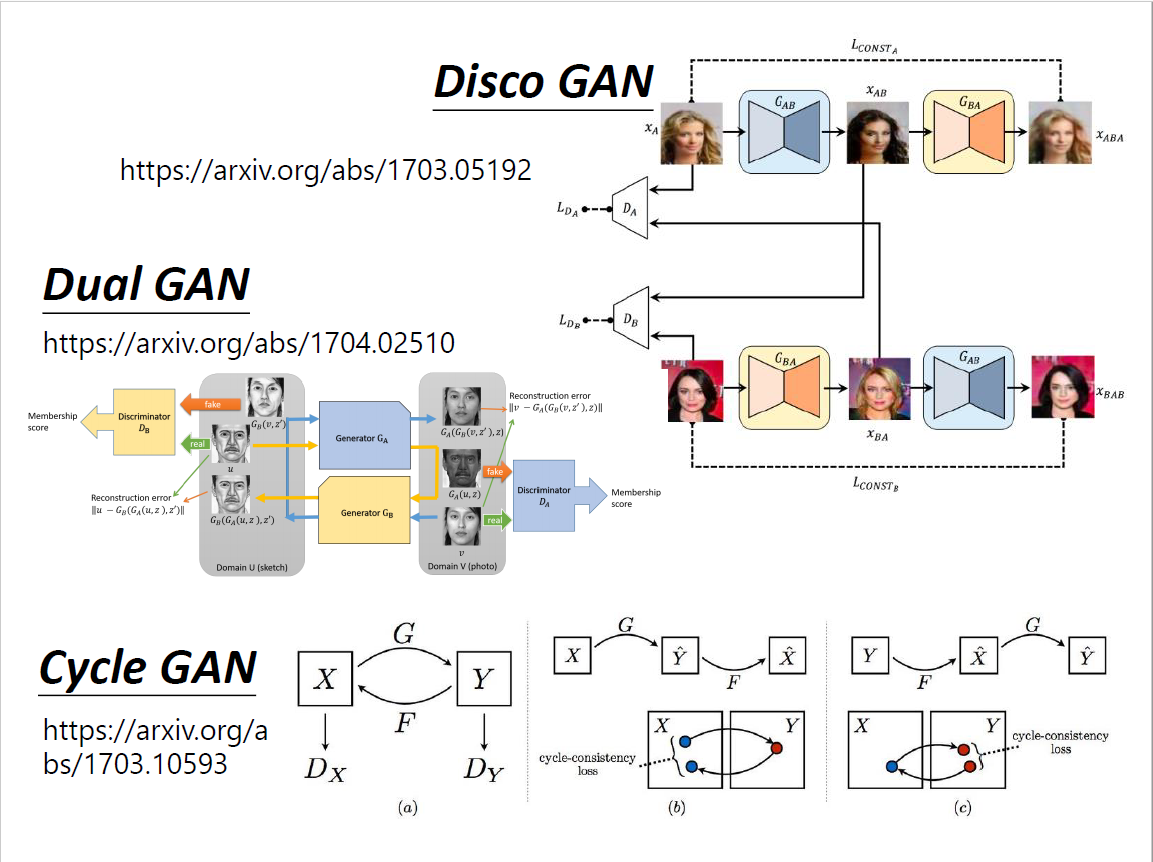
Cycle GAN
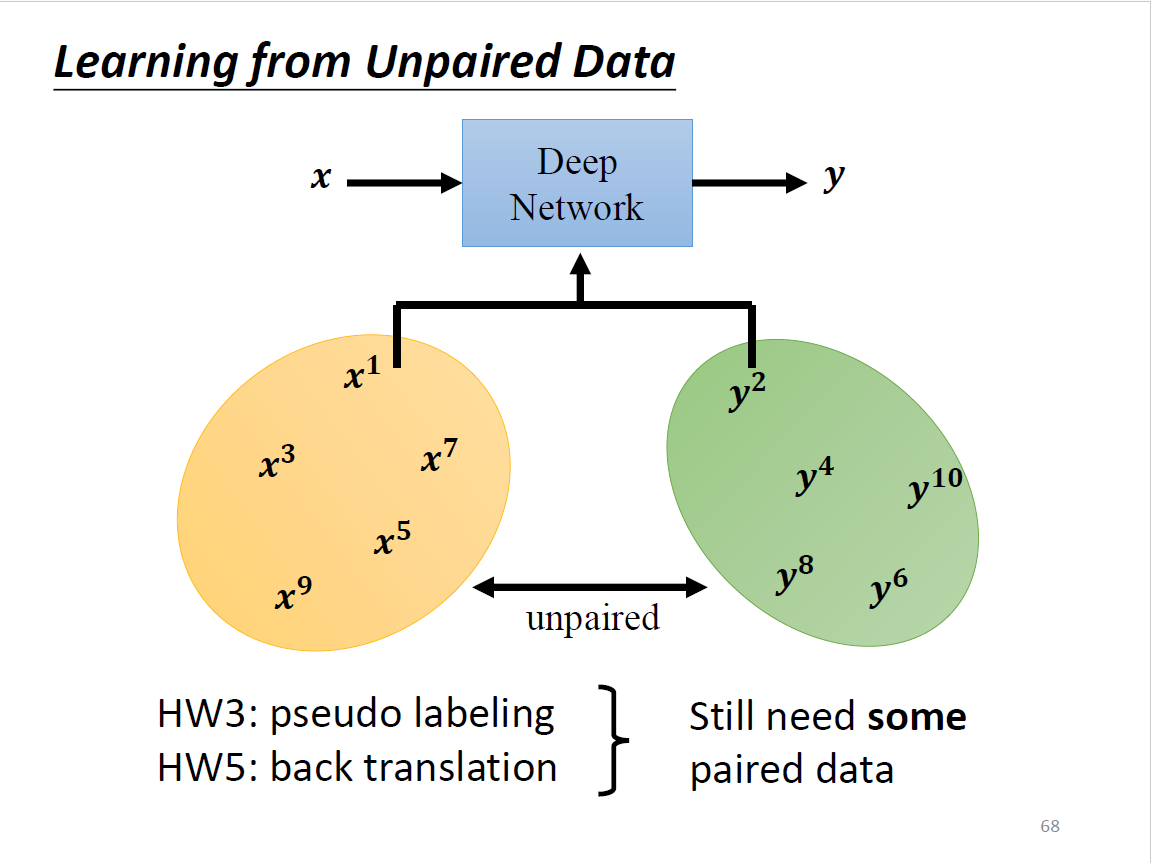
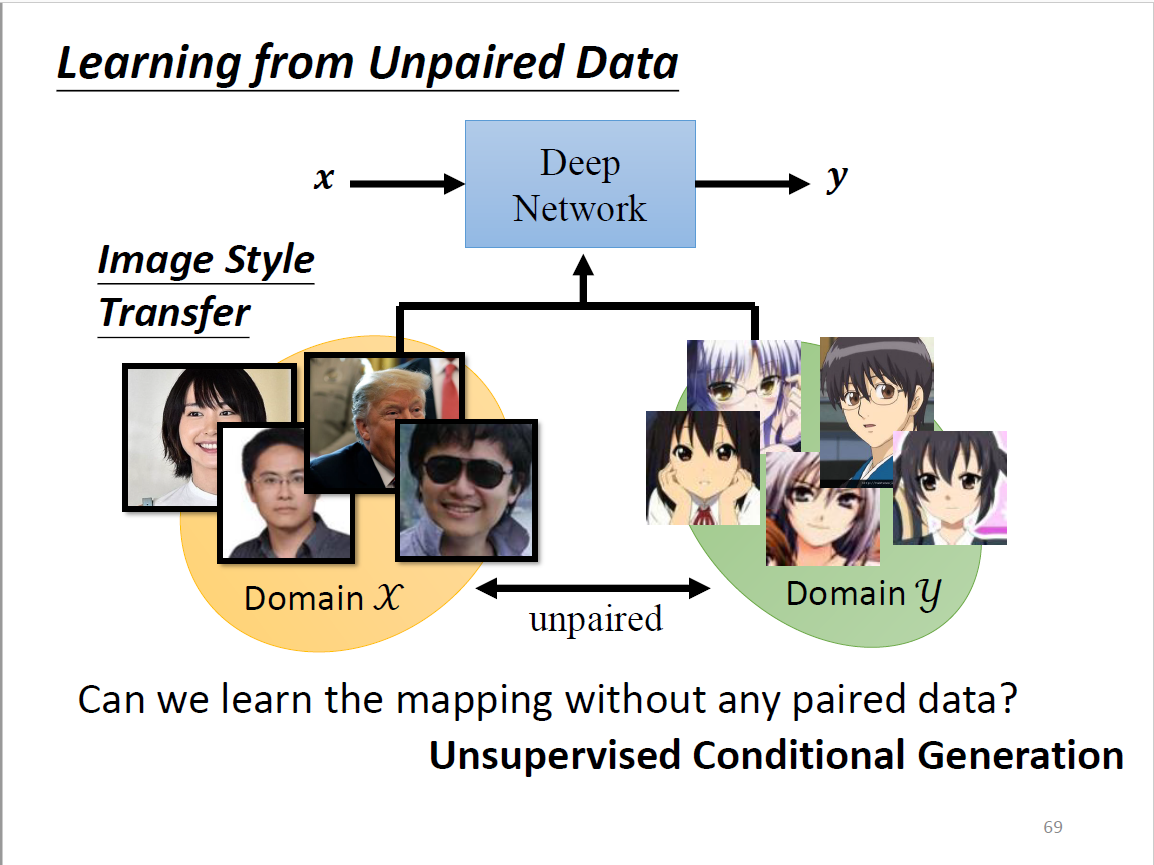
Learning from Unpaired Data
没有成对的资料,unlabelled data,属于semi-supervised learning HW3和HW5提供了不同的方法,但仍需要一部分的标注资料
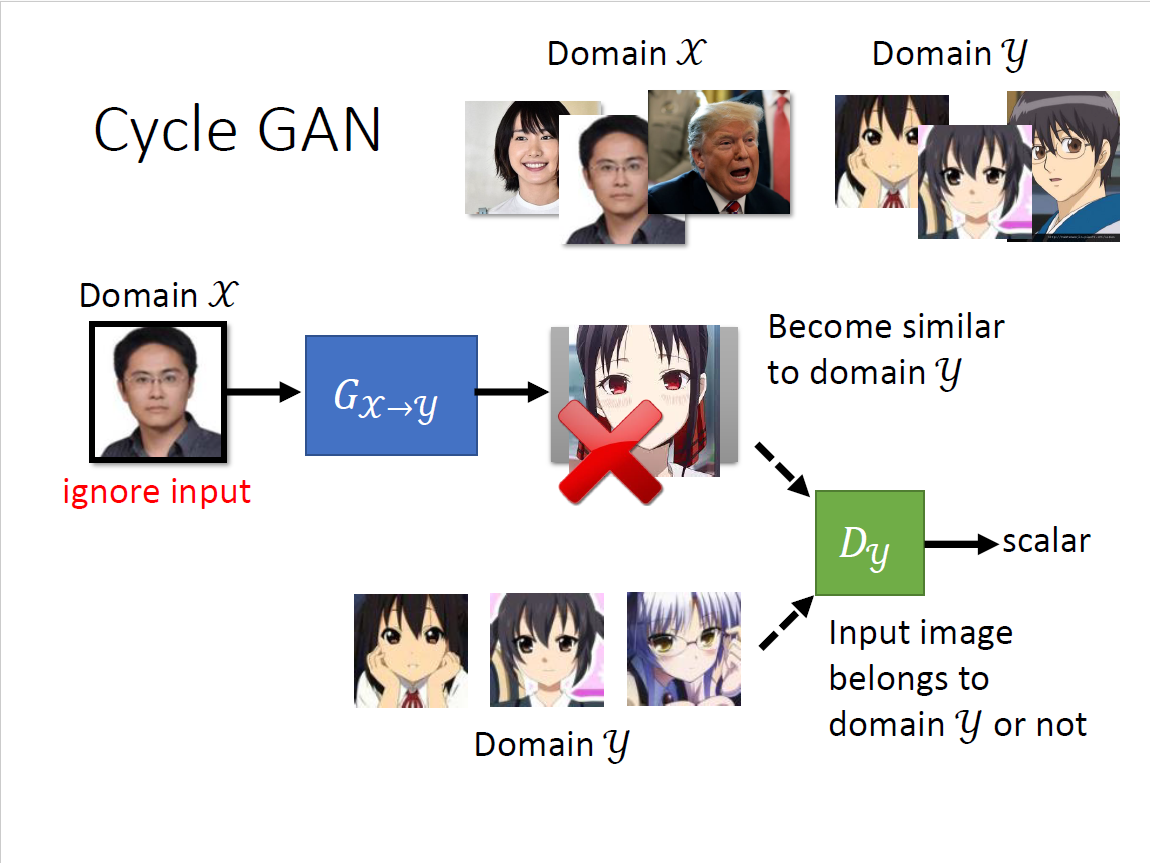
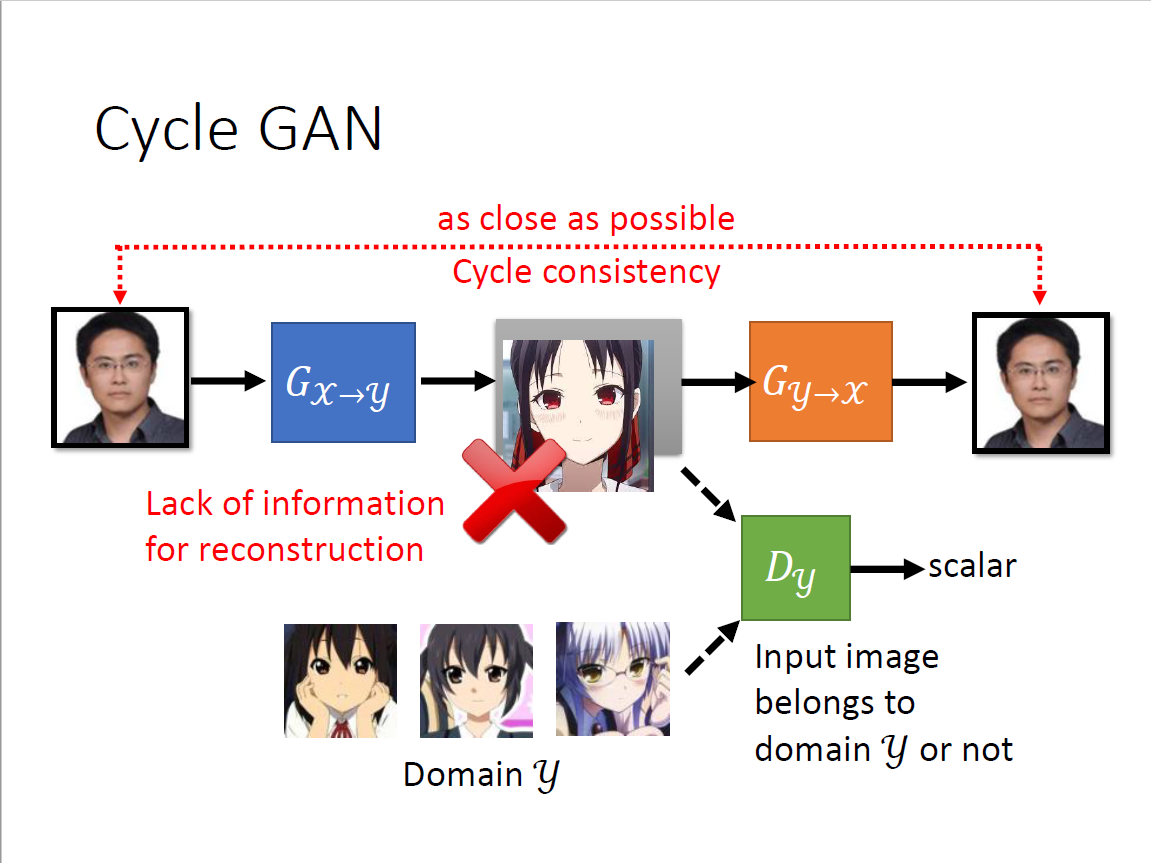
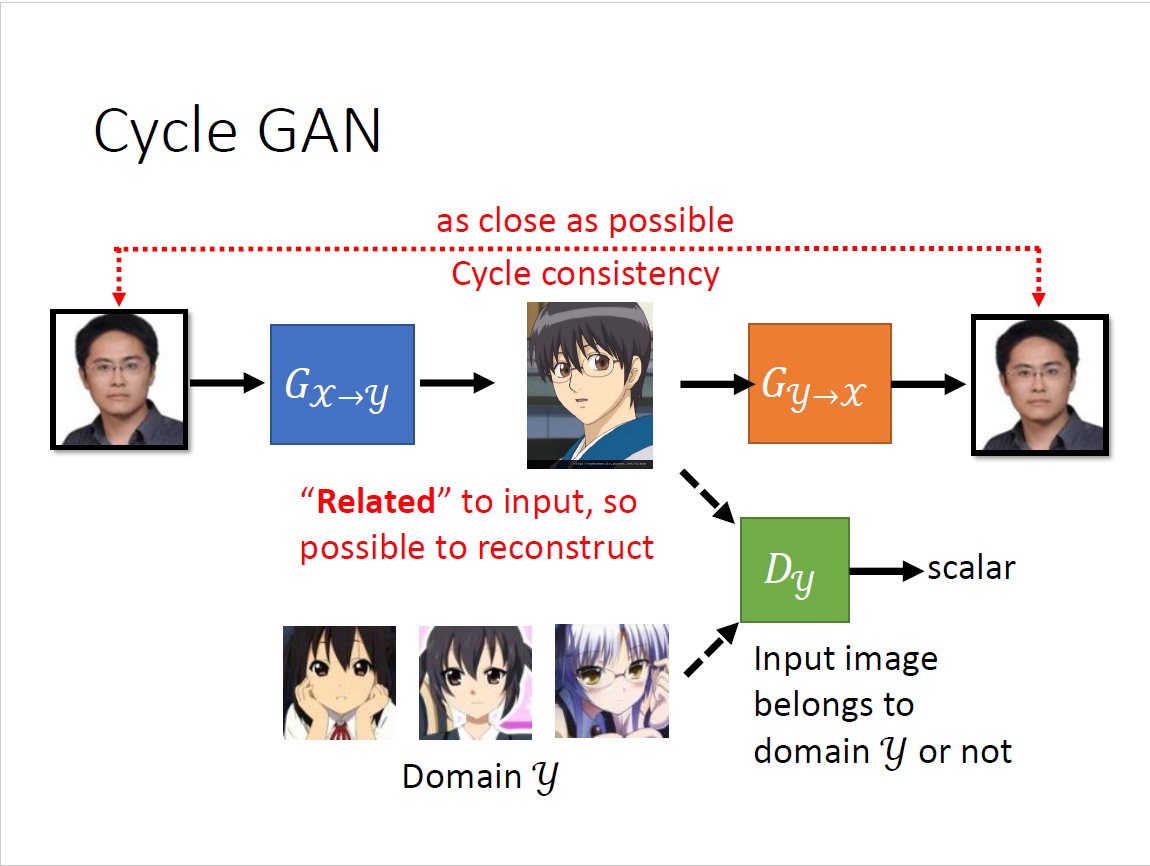
一点成对的资料都没有?影像风格转换(真人图片→二次元头像) 思考:仅仅是输入从Gaussian distribution里sample变成真人data里sample吗? 回到conditional GAN的初衷来,输入和输出可以无关,输入作为Gaussian noise 问题:我们没有办法像conditional GAN那样拿出成对的资料 希望$G_{x\to y}$和$G_{y\to x}$的输入和输出越接近越好,也即两个向量距离比较小 为了还原,必须$G_{x\to y}$的输出要跟输入有一定关系,否则无法还原回去 设想:
- $G_{x\to y}$左右翻转,$G_{y\to x}$同样是左右翻转,就学到了很奇怪的转换
- 没有很好的解决方法,但实际上很少出现这种情况
- 但甚至不加第二个network也行,计算机很懒,倾向于输出很像的东西
- 它不愿意做太复杂的变换,比如有眼睛就输出眼睛,但理论上没有保障
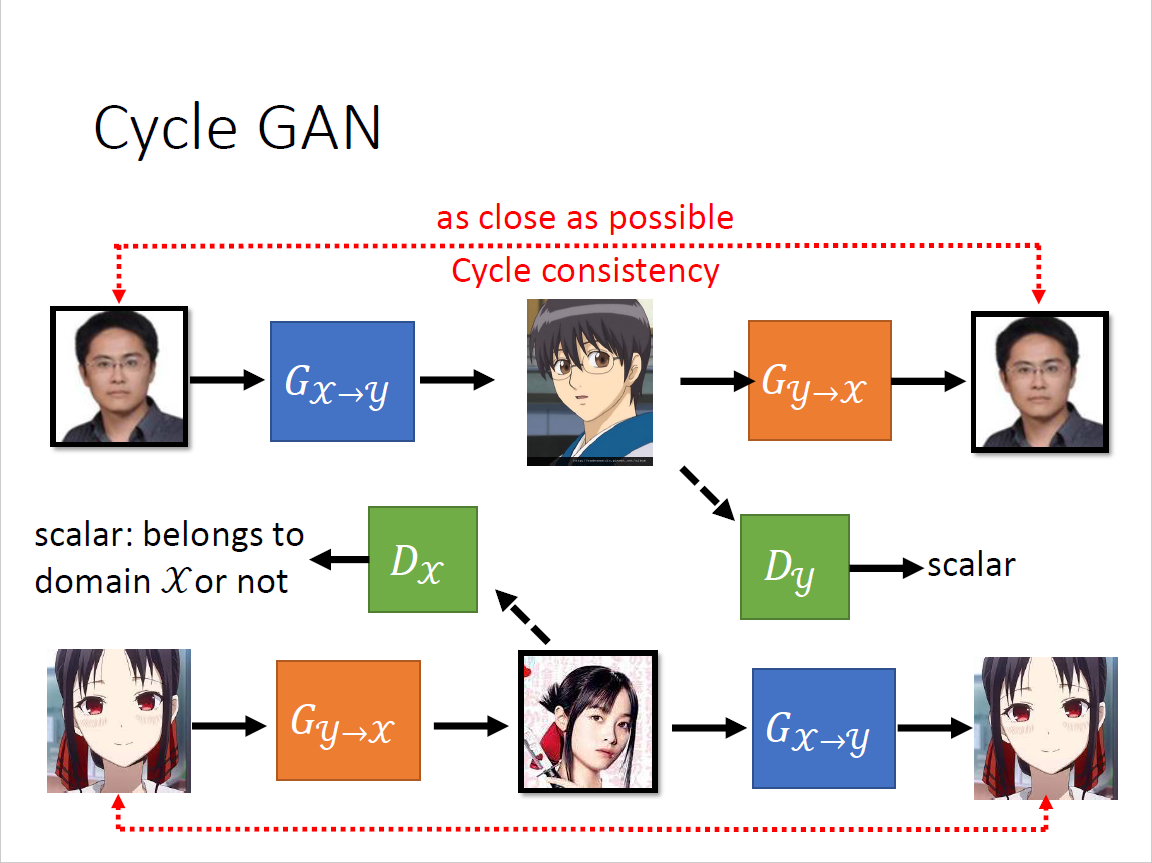
思维再更开放,可以创造一个镜像问题,合起来就是Cycle GAN
Related Work
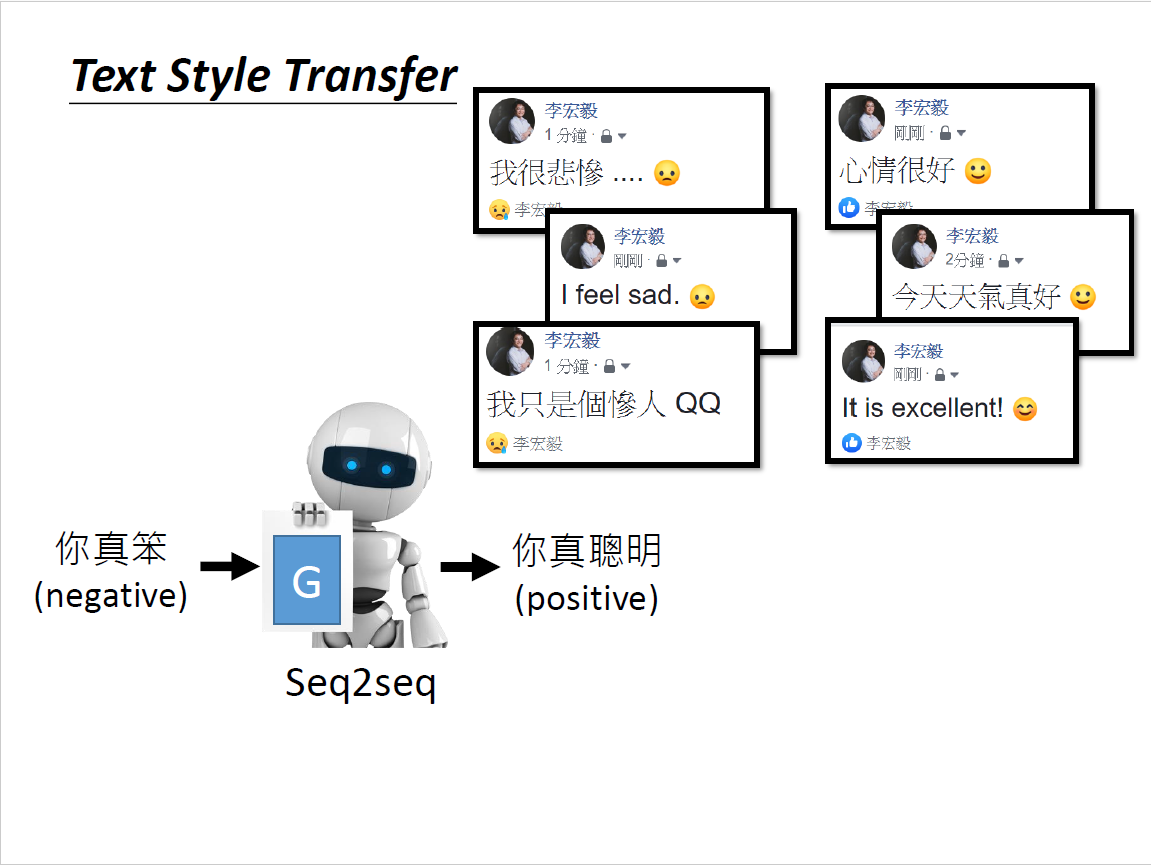
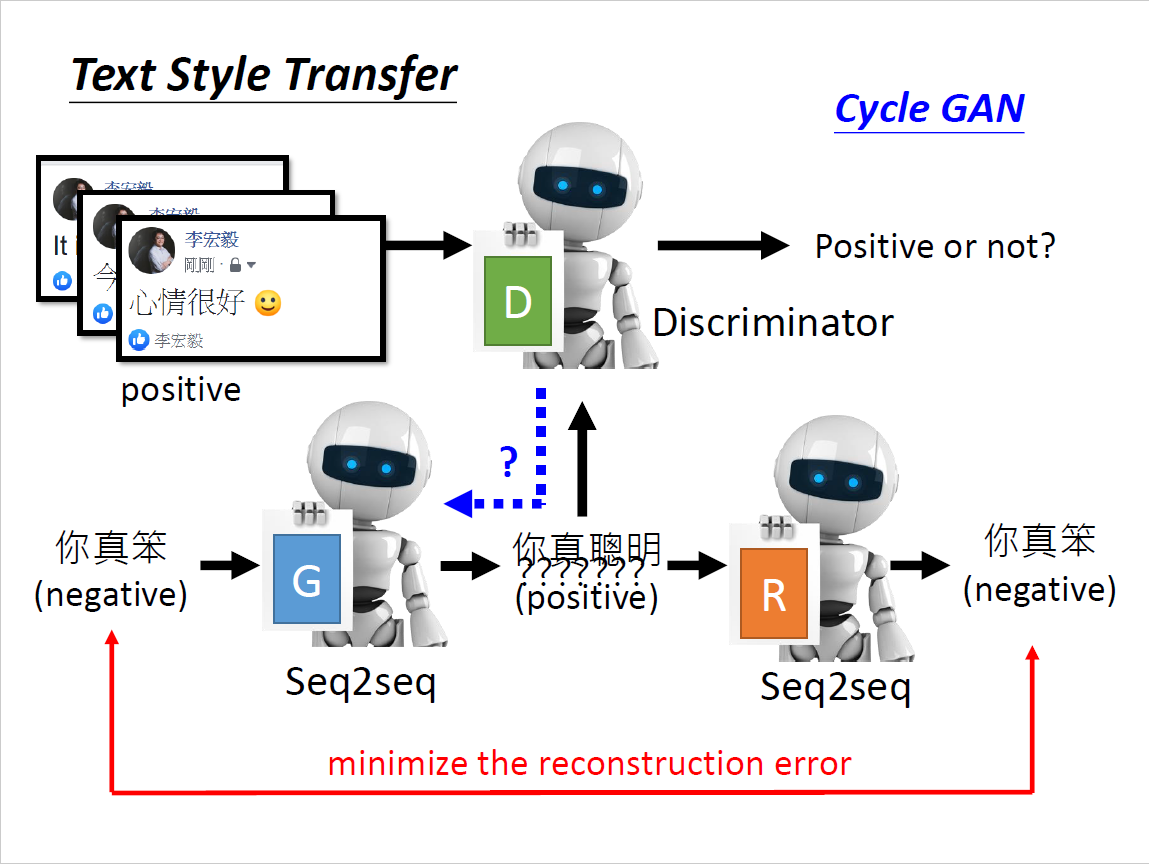
文字风格转换(Transformer)
多种风格转换