 architecture
architecture
Tips
ImageNet上训练一个CNN可以帮助绝大多数CV的问题,但从前没有一个神经网络可以适用于绝大多数NLP的问题。BERT就是这个工具。
Abstract
BERT = Bidirectional Encoder Representations from Transformers GPT:单向 BERT:双向 ELMo:基于RNN BERT:基于Transformer 在很多语言问题上,只用加一个额外的输出层就可以得出不错的结果。
概念上更加简单,实验更好。
讲模型好的时候:绝对精度,相对好处
Introduction
两类任务: 1. 句子任务,建模句子之间的关系/情绪识别 2. 词源任务,NER,输出一些细腻度词元层面的输出
BERT不是第一个提出NLP pre-train的,但是让它“出圈”了
两种预训练应用策略: 1. 基于特征(feature-based) → ELMo 作为额外特征一起输入模型里面 比较常用 2. 基于微调(fine-tuning) → GPT 预训练好的参数会在下游进行微调
两种途径都是使用一个相同的目标函数,单向语言模型(预测模型,不可能给两句猜中间)具有局限性
看完整个句子再选答案,而非一个个往下走,把两个方向的信息都放进来
用到的是MLM(masked language model) → 受Cloze task的影响 1953年! 带掩码,可以看左右的信息。类似完形填空。 随机选一些词源,把它们盖住,目标函数是预测被盖住的那些字。
任务:给定两个句子,判断是否相邻。
贡献: 1. 展示了双向信息的重要性 2. 不会对特定任务特定模型进行改动,第一个在句子层面和词源层面实验效果都很好的fine-tune模型 3. 开源
Related Work
Unsupervised Feature-based Approaches
Unsupervised Fine-tuning Approaches
如GPT
Transfer Learning from Supervised Data
自然语言推断和机器翻译数据集上训练 部分效果不好的原因 1. 两个任务比较特别 2. 数据量其实还是远远不够
BERT证明unsupervised大量数据集效果好过supervised小数据集,也在被CV领域所采用
BERT
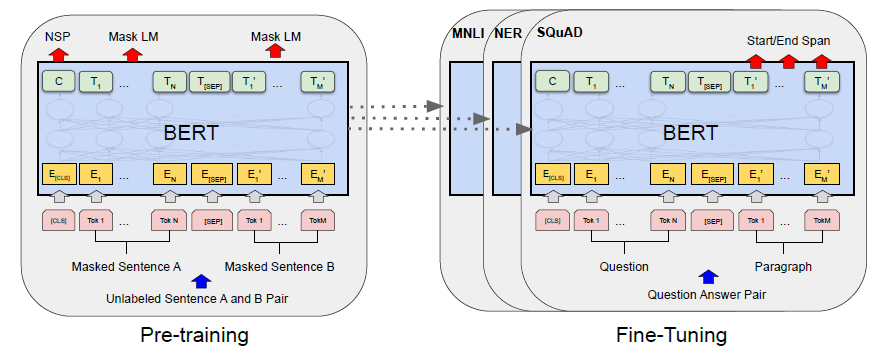
pre-training和fine-tuning的概念(必要的科普和说明)
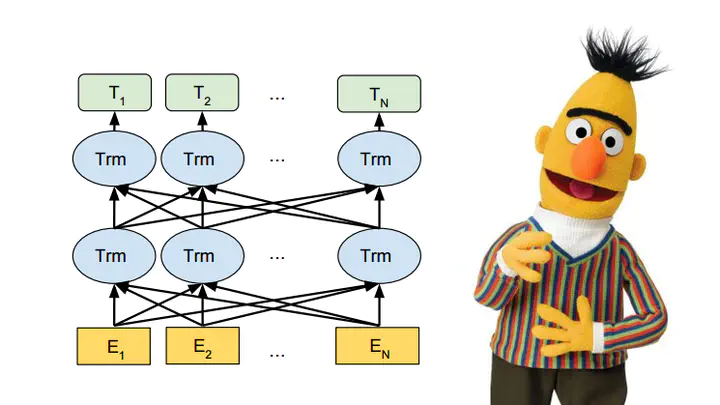
Model Architecture
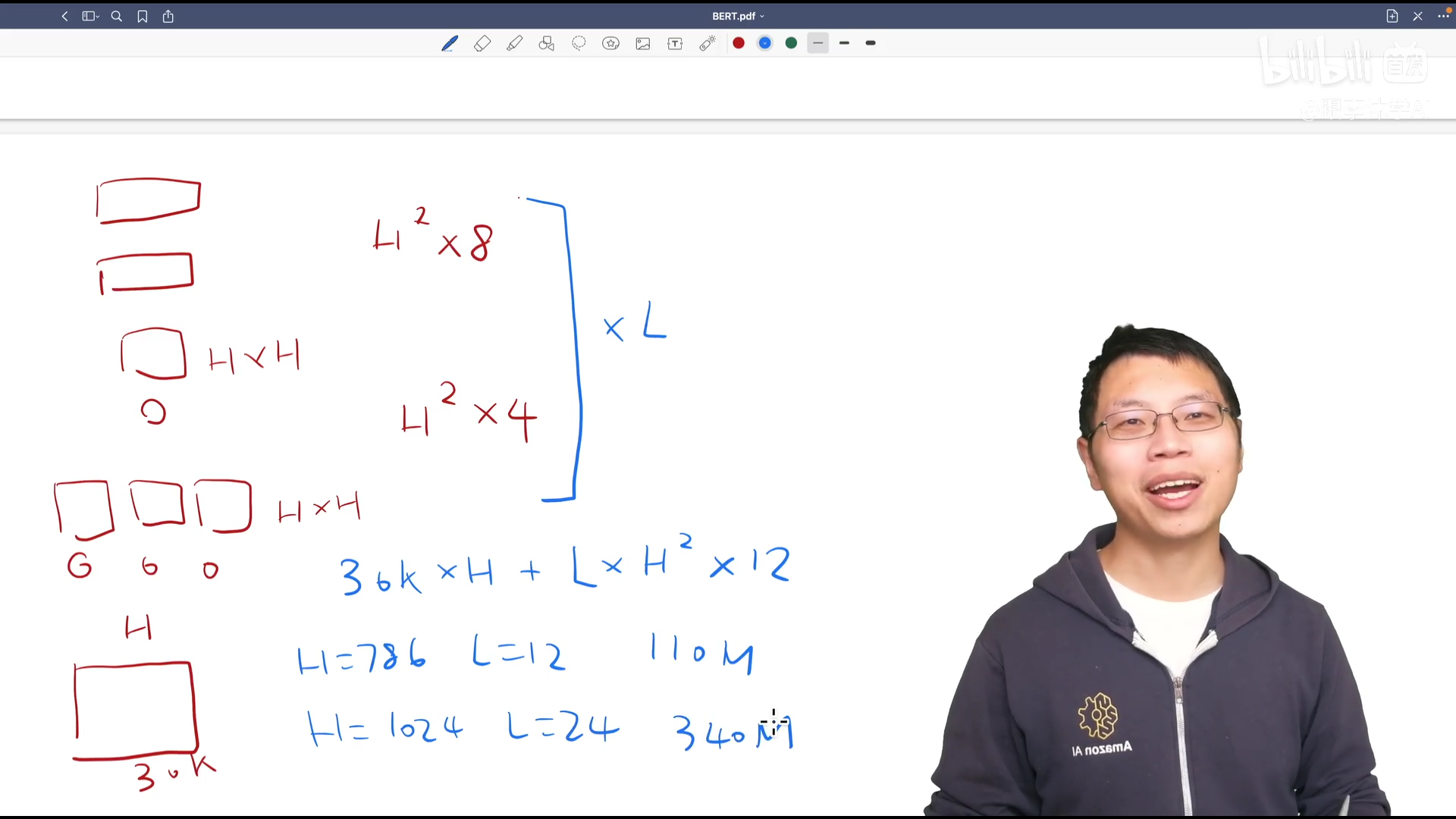
调了三个参数 L, transformer块个数 H, 隐藏层大小 A, 多头”头“个数
分别有BERTBASE和BERTLARGE 模型复杂度跟层数线性关系,宽度平方关系
BERT跟GPT参数个数差不多
参数计算:
Input/Output Representations
输入:可以是一个句子,可以是一个句子对 输入是一个sequence,只有Encoder,transformer输入是一个序列对(有Encoder和Decoder)
切词方法是WordPiece 原有问题:空格切词一个词作为一个token,数据量比较大,词典大小特别大,百万级别参数全在Embedding层上面 现有方式:如果词出现频率不大,就切开看子序列(比如词根),保留经常出现的子序列,可以用较小的词典表示较大的文本
CLS输入:分类
SEP:两个句子,separate作为特殊token,或者学习一个嵌入层判断是第一个句子还是第二个句子
对每个词元进入BERT的向量表示 = 词元本身embedding + 所在句子embedding +所在位置embedding
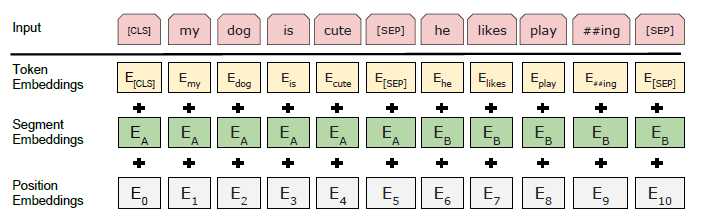
词元序列 → 向量序列 每一个transformer块是一个词元,从上往下为词元embedding,第二个为句子embedding,第三个为位置embedding(embedding本身就是向量,维度一样就可以相加)
Pre-training BERT
预训练有两个东西比较重要 1. 目标函数 2. 训练数据
Task #1: Masked-LM
WordPiece生成的词元会有15%的概率随机替换成一个掩码 特殊词元如第一个词元或分隔词元不做替换
问题:做掩码的时候 → 替换成特殊token,即[MASK] 微调的时候没有这个目标函数?
15%里: 80% MASK 10% 随机替换 10% 不改变,但用于预测 基于Ablation Study

Task #2: Next Sentence Prediction(NSP)
输入序列有两个句子,A和B,50%正例负例 加入目标函数可以极大增加准确性
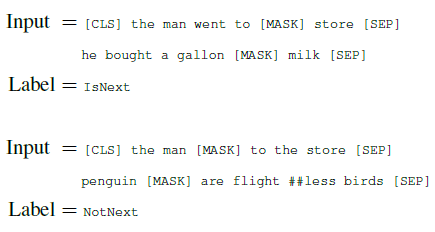
flightless
被拆开成flight和less
Pre-training data
用到了BooksCorpus(800M words)和English Wikipedia(2,500M words) 应该用文本层面的数据集而非随机打乱的句子,因为transformer可以处理长序列
Fine-tuning BERT
self attention在两端之间可以相互看,而原来的encoder看不到decoder信息
跟预训练比微调一般比较便宜
Experiments
GLUE
句子层面的任务,把第一个特殊词元CLS最后的向量拿出来,学习一个输出层W,放进去之后softmax得到标号,多类分类问题
SQuAD v1.1
斯坦福QA数据集,答案在原文中,找出对应片段的开始和结尾 对每个词元判断是否是答案开头和结尾 学习两个向量,S ∈ RH和E ∈ RH,即答案开始和最后的概率 $$ P_i=\frac{e^{S \cdot T_{i}}}{\sum_{j}e^{S \cdot T_j}} $$ 注:微调的时候用3个epoch,学习率$5e^{-5}$,batch size 为32,实际上非常不稳定 epoch应该改大
BERT使用Adam不完全版,需要训练较长的时间
SQuAD v2.0
SWAG
判断句子之间的关系
Ablation Studies
Effect of Pre-training Tasks
双向LSTM,去除掉BERT中每一块作用,看贡献 去掉下一个句子,以及从左看到右(不带掩码)
Effect of Model Size
模型变大的效用
Feature-based Approach with BERT
没有微调好使
Conclusion
主要把前人的任务拓展到深的双向的架构上面。融合GPT + ELMo.
Evaluation
做生成类的东西没那么方便了 有完整的解决思路
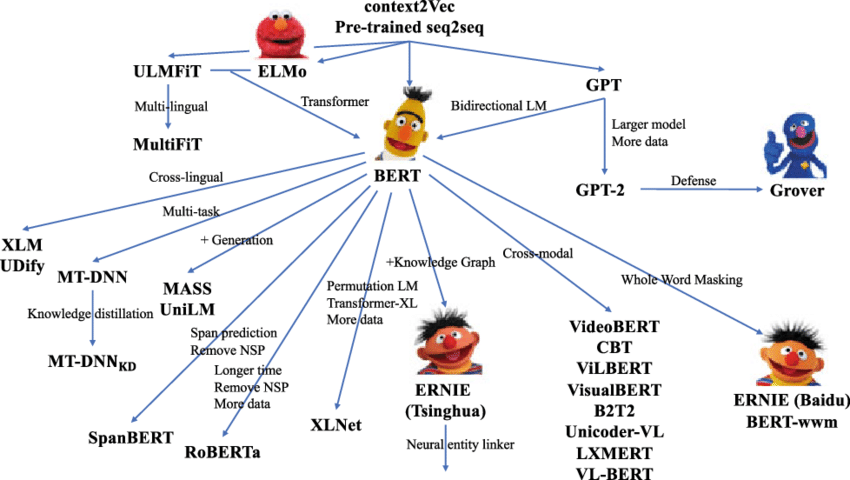
可扩展性很强(图源THUNLP)